PETL_AST
1.0.0
Dieses Repository enthält den offiziellen Code der Papiere: Parameter-effizientes Übertragungslernen von Audiospektrogrenzransformatoren [1] ( zur Veröffentlichung im IEEE MLSP-Workshop 2024 angenommen ) und eine effiziente Feinabstimmung von Audio-Spektrogramm-Transformatoren über Soft-Mischung von Adaptern [2] ( akzeptiert für die Veröffentlichung für die Veröffentlichung bei Interspeech 2024 ).
Beide Papiere untersuchen, wie PETL -Methoden (Parameter-effizientes Transferlernen) auf das ASTI-Modell des Audiospektrogramms (AST) für verschiedene Audio-/Sprach-Downstream-Aufgaben angewendet werden. Während [1] einen umfassenden Überblick über die PETL-Methoden (Eingabeaufbau, Lora, Adapter) unter verschiedenen Szenarien und Einschränkungen bietet, [2] untersucht, wie die Mischung der Expertenarchitektur für PETL effizient nutzt.
Im Folgenden fügen wir alle Details hinzu, um unsere Ergebnisse zu replizieren. Wichtig : Stellen Sie sicher, dass Sie eine Umgebung einrichten, die mit der für unsere Experimente verwendeten kompatibel ist. Installieren Sie daher dieselben Paketeversionen mit der Anforderungen.txt -Datei.
Umberto Cappellazzo, Daniele Falavigna, Alessio Bruutti, Mirco Ravanelli
Das Papier wurde auf dem IEEE MLSP Workshop 2024 akzeptiert . In diesem Artikel wird die Verwendung verschiedener PETL -Methoden untersucht, die für verschiedene Audio- und Sprachverarbeitungsaufgaben angewendet werden. Darüber hinaus schlagen wir ein neues Adapterdesign vor, das das Faltungsmodul des Konformermodells ausnutzt, was zu einer überlegenen Leistung gegenüber den Standard-PETL-Ansätzen führt und die Leistungsparität mit vollständiger Feinabstimmung überträgt oder erreicht, indem nur 0,29% der Parameter aktualisiert werden.
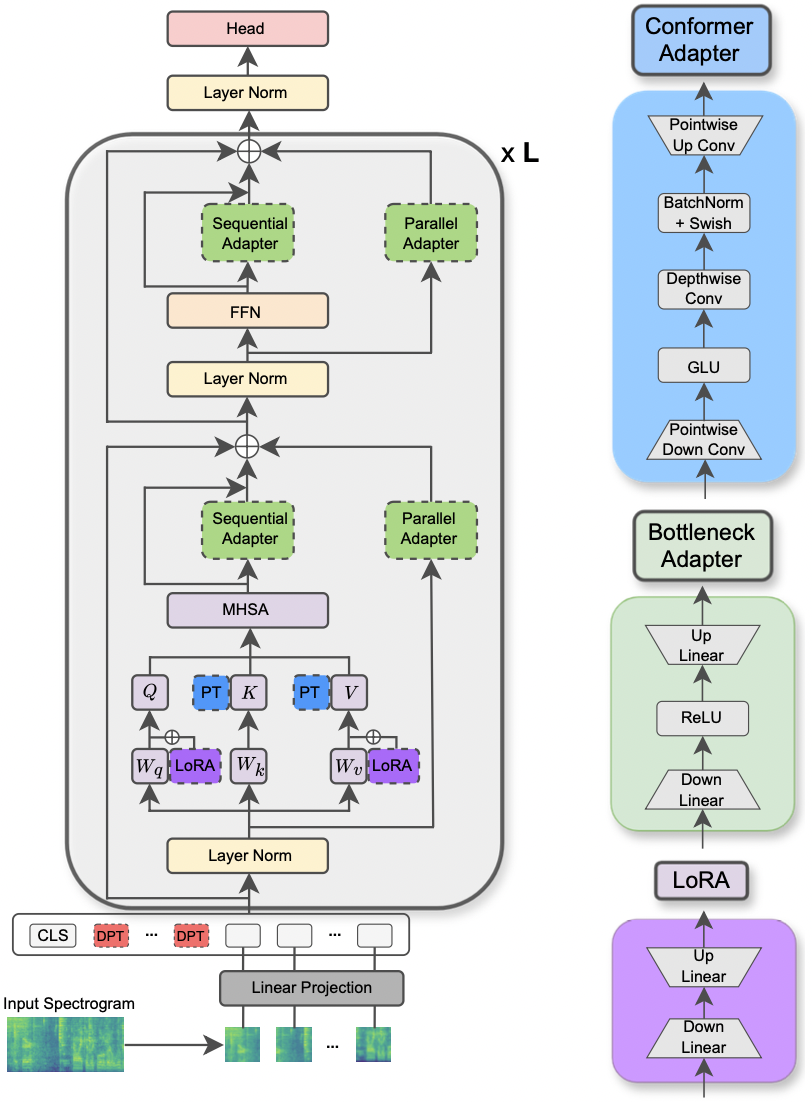 |
|---|
| Abbildung des AST -Modells und der PETL -Methoden. |
Die angeforderten Bibliotheken zum Ausführen der Experimente sind in der Datei der Anforderungen.txt aufgeführt. Führen Sie den folgenden Befehl aus, um sie zu installieren.
pip install -r requirements.txt
Ich verwende Gewichte und Vorurteile (https://wandb.ai/site), um meine Experimente zu verfolgen (ich empfehle es herzlich). Trotzdem können Sie es deaktivieren, indem Sie in der Befehlszeile --use_wandb = False .
Ich gehe davon aus, dass der Benutzer die Datensätze bereits von sich selbst heruntergeladen hat.
Um ein Experiment durchzuführen, müssen Sie alles, was Sie brauchen, den Befehl python3 main.py verwenden, gefolgt von einigen Argumenten, die an die Befehlszeile weitergegeben werden, um die Einstellung anzugeben. Die obligatorischen Parameter sind:
--data_path : Der Pfad zum Ordner, der den Datensatz enthält.--dataset_name : Der ausgewählte Datensatz. Ab sofort sind 5 Datensätze verfügbar: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] .--method : Die ausgewählte PETL-Methode. Eine Liste der unterstützten PETL-Methoden folgt: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] . Bitte schauen Sie sich das andere Papier an, um ein Experiment mit dichter/weichem MOA durchzuführen.--is_AST : Wenn es auf True gesetzt ist, verwendet es das AST-Vorausgebildete Modell. Wenn es auf False eingestellt ist, wird das vorgebildete WAV2VEC 2.0-Modell verwendet.main.py an, um eine detaillierte Beschreibung zu erhalten.hparams/train.yaml geprüft und geändert werden. Die aktuellen Werte entsprechen denen, die wir für unsere Experimente verwendet haben und die zu den besten Ergebnissen führten.Jede PETL -Methode verfügt über einige spezifische Parameter. Wir geben unten eine kurze Beschreibung. Beachten Sie, dass wir hier vermeiden, dass die Referenzen für die Kürze einbezogen werden. Weitere Informationen finden Sie in der Zeitung.
reduction_rate_adapter -> Es regiert das Engpassendim des Adaptermoduls (z. B. wenn d die verborgene Dimension ist und RR die Reduktionsrate ist, dann ist das Dim des Adapters d /rr); seq_or_par -> ob das Adapter parallel oder sequentiell einfügt; adapter_type -> entweder Pfeiffer oder Houlsby -Konfiguration; adapter_block -> entweder Engpass oder Konformer (unser vorgeschlagenes Adapterdesign); apply_residual -> ob anwenden verbleibende Verbindungen anwenden oder nicht. Wie in der Arbeit berichtet, sollte der parallele Adapter auf Residuen verzichten, während sequentielle Adapter von Residuen profitieren.prompt_len_prompt > Wie viele Eingabeaufforderungen zu verwenden; is_deep_prompt > Setzen Sie auf True , wenn Sie eine tiefe Eingabeaufforderung (DPT) aktivieren möchten, sonst flache Eingabeaufforderung (SPT); drop_prompt -> Die Abbrecherquote für die Eingabeaufforderungen. In unseren Experimenten setzen wir es auf 0. .reduction_rate_lora -> Siehe reduction_rate_adapter ; alpha_lora -> Die Lora_Alpha wie im Originalpapier definiert. Dies wird zur Skalierung verwendet (z. B. s = alpha_lora/rr).Angenommen, wir möchten den Adapter mit Konfigurationskonformer, Parallel, Pfeiffer, RR = 64 testen und ihn für das AST -Modell auf dem FSC -Datensatz testen. Dann ist der Befehl zum Ausführen:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer ' Wenn Sie nur wenige Lernexperimente ausführen möchten, müssen Sie nur das Flag --is_few_shot_exp auf True festlegen und die Anzahl der Beispiele pro Klasse angeben --few_shot_samples .
Bitte wenden Sie sich an mich unter: UmbertoCappellazzo [at] gmail [dot] com für jede Frage.
Wir erkennen die Unterstützung der Digital Research Alliance of Canada (Alliancecan.ca) an.
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti
Das Papier wurde bei Interspeech 2024 akzeptiert . Es untersucht die Verwendung von Experten (MOE) zur effizienten Feinabstimmung von AST. Insbesondere passen wir die jüngste Soft MOE-Methode an unsere parametereffiziente Einstellung an, wobei jeder Experte durch ein Adaptermodul dargestellt wird. Wir nennen es Soft-MoA (weiche Mischung aus Adaptern). Soft-MoA erreicht die Leistungsparität mit dem dichten Gegenstück (dichter-moa), während die Rechenkosten abschneiden. Darüber hinaus zeigt es eine überlegene Leistung gegenüber dem traditionellen Einzeladapter.
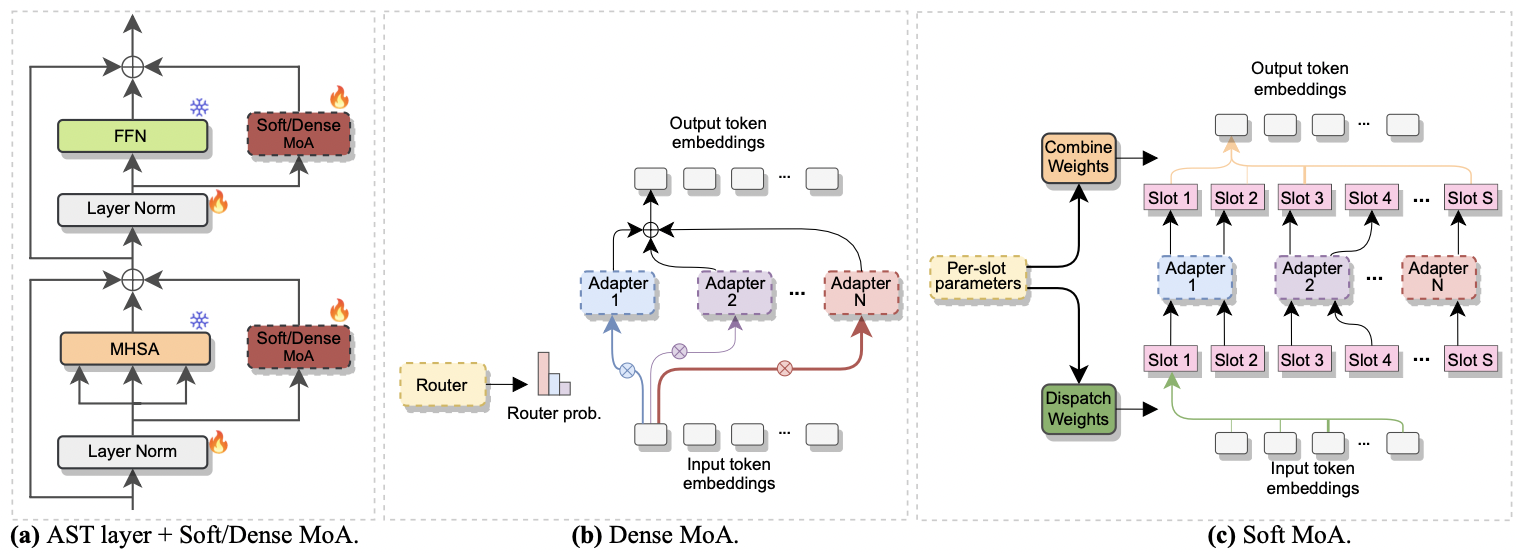 |
|---|
| A) Adaptereinfügung in jede AST -Schicht. b) dichter-moa. c) Soft-Moa. |
Ein Experiment mit dichtem und weichem MOA zu führen ist ein Kinderspiel. Wir befolgen das gleiche Verfahren, das wir für Papier verwendet haben [1] . Wir müssen nur den Parameter --method auf Dense-MoA oder Soft-MoA einstellen und einige Ad-hoc-Parameter angeben:
--reduction_rate_moa : Genau wie für die anderen PETL-Methoden müssen wir die Reduktionsrate für jeden Adapter-Experten angeben. Je höher die Reduktionsrate ist, desto kleiner ist die Engpässe.--adapter_type_moa : Pfeiffer oder Houlsby -Konfiguration.--location_moa : Ob Sie die weichen/dichten MOA-Schichten parallel zu den MHSA- oder FFN- Blöcken anwenden sollen. If --adapter_type_moa == Houlsby, MHSA und FFN werden auomatisch ausgewählt.--adapter_module_moa : Die Art des Adapters. Wir unterstützen Abgas und Convpass ab sofort.--num_adapters : Wie viele Adapter werden für jede weiche/dichte MOA-Schicht verwendet. In unseren Experimenten liegt dieser Wert zwischen 2 und 15.--num_slots : Die Anzahl der in Soft-MoA verwendeten Slots. Normalerweise wird es auf 1 oder 2 eingestellt. [ NB : Nur in Soft-MoA verwendet]--normalize : Ob L2 den Eingangsvektor und die PHI-Matrix normalisieren, wie im ursprünglichen Soft MOE-Papier vorgeschlagen (siehe Abschnitt 2.3, "Normalisierung"). Wie in der Arbeit angegeben, hat der Normalisierungsvorgang nur geringe Auswirkungen, wenn die versteckte Größe des Modells in unserem Fall gering ist (z. B. 768), sodass wir die Normalisierung nicht verwendet haben. [ NB : Nur in Soft-MoA verwendet]Angenommen, wir möchten Soft-MoA im FSC-Datensatz testen. Außerdem entscheiden wir uns dafür, die Soft-MoA-Schicht nur in die MHSA-Schichten aufzunehmen, und wir verwenden 7 Botteneck-Adapter. Dann ist der Befehl zum Ausführen:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

