PETL_AST
1.0.0
Este repositório contém o código oficial dos artigos: aprendizado de transferência eficiente em parâmetro de transformadores de espectrograma de áudio [1] ( aceito para publicação no workshop de 2024 IEEE MLSP ) e eficiente-vinculação fina dos transformadores de espectrograma de áudio via mixagem suave de adaptadores [2] ( aceito para publicação em inter-recurada 2024 ).
Ambos os trabalhos estudam como aplicar os métodos de aprendizado de transferência eficiente em parâmetro ( PETL ) ao modelo de transformador de espectrograma de áudio (AST) para várias tarefas a jusante de áudio/fala. Enquanto [1] fornece uma visão abrangente dos métodos PETL (ajuste rápido, Lora, adaptadores) em diferentes cenários e restrições, [2] explora como aproveitar com eficiência a mistura da arquitetura de especialistas para PETL.
Abaixo, incluímos todos os detalhes para replicar nossos resultados. IMPORTANTE : Certifique -se de configurar um ambiente compatível com o que usamos para nossas experiências; portanto, instale as mesmas versões de pacotes usando o arquivo requisitos.txt .
Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti, Mirco Ravanelli
O artigo foi aceito no workshop IEEE MLSP de 2024 . Este artigo explora o uso de diferentes métodos PETL aplicados ao modelo de transformador de espectrograma de áudio para várias tarefas de processamento de áudio e fala. Além disso, propomos um novo design de adaptador que explora o módulo de convolução do modelo conformador, levando a um desempenho superior sobre as abordagens PETL padrão e superando ou alcançando a paridade de desempenho com ajuste completo, atualizando apenas 0,29% dos parâmetros.
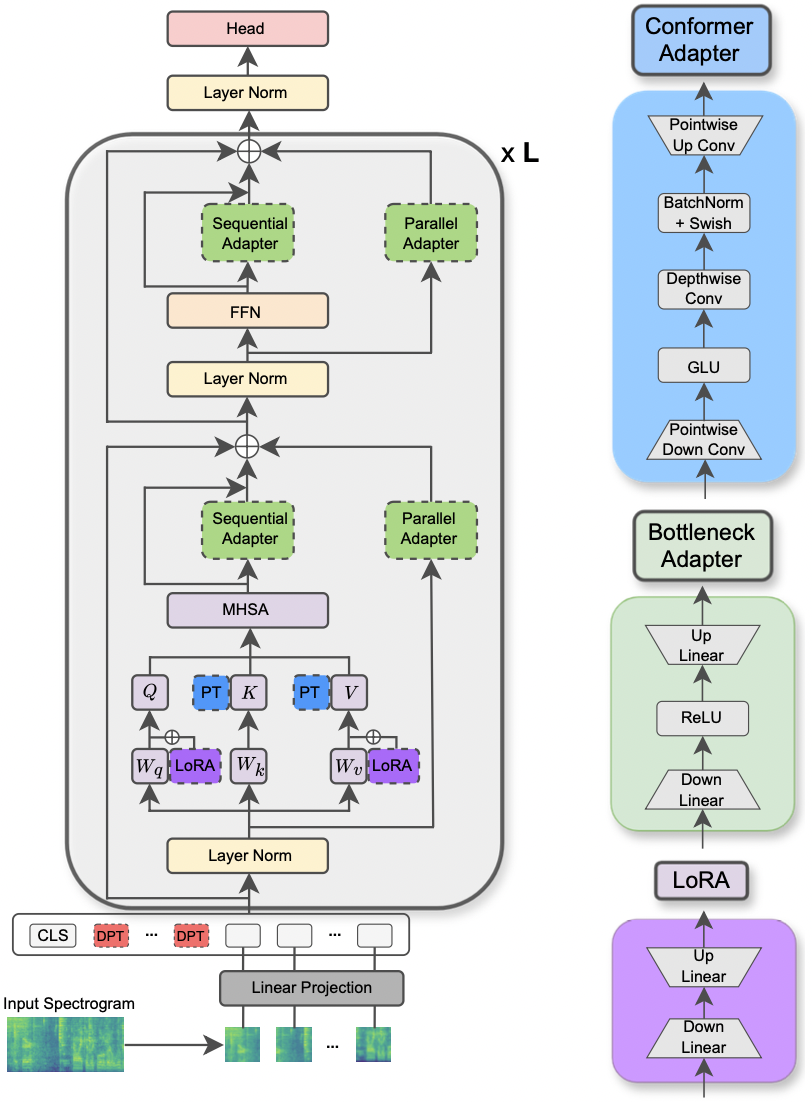 |
|---|
| Ilustração do modelo AST e dos métodos PETL. |
As bibliotecas solicitadas para executar as experiências estão listadas no arquivo requisitos.txt. Execute o comando abaixo para instalá -los.
pip install -r requirements.txt
Eu uso pesos e vieses (https://wandb.ai/site) para rastrear meus experimentos (eu recomendo calorosamente). No entanto, você pode desativá -lo definindo --use_wandb = False na linha de comando.
Espero que o usuário já tenha baixado os conjuntos de dados por si mesma.
Para executar um experimento, tudo o que você precisa é usar o comando python3 main.py seguido por alguns argumentos transmitidos à linha de comando para especificar a configuração. Os parâmetros obrigatórios são:
--data_path : o caminho para a pasta que contém o conjunto de dados.--dataset_name : o conjunto de dados selecionado. A partir de agora, 5 conjuntos de dados estão disponíveis: ['FSC', 'ESC-50', 'urbansound8k', 'GSC', 'IEMOCAP'] .--method : o método PETL selecionado. Uma lista de métodos PETL suportados segue-se: ['linear', 'full-FT', 'adapter', 'prompt-tuning', 'prefix-tuning', 'LoRA', 'BitFit', 'Dense-MoA', 'Soft-MoA'] . Por favor, confira o outro papel para executar um experimento com densidade/moa soft.--is_AST : se definido como true, ele usa o modelo AST pré-treinado. Se definido como false, ele emprega o modelo pré-treinado WAV2VEC 2.0.main.py para obter uma descrição detalhada.hparams/train.yaml . Os valores atuais correspondem aos que usamos para nossos experimentos e isso levou aos melhores resultados.Cada método PETL vem com alguns parâmetros específicos. Fornecemos uma breve descrição abaixo. Observe que aqui evitamos incluir as referências de brevidade, consulte o artigo.
reduction_rate_adapter -> Rege o gargalo do módulo do adaptador (por exemplo, se D é a dimensão oculta e RR é a taxa de redução, então o escurecimento do adaptador é D /RR); seq_or_par -> se deve inserir o adaptador paralelo ou sequencialmente; adapter_type -> Configuração Pfeiffer ou Houlsby; adapter_block -> Bottleneck ou Conformer (nosso design de adaptador proposto); apply_residual -> Aplicar conexões residuais ou não. Conforme relatado no artigo, o adaptador paralelo deve dispensar os resíduos, enquanto o adaptador seqüencial se beneficia dos resíduos.prompt_len_prompt > Quantos avisos para usar; is_deep_prompt > Defina como True se você deseja ativar o ajuste rápido (DPT), caso contrário, o tunning rápido (SPT); drop_prompt -> A taxa de abandono para os prompts. Em nossos experimentos, definimos para 0. .reduction_rate_lora -> Consulte reduction_rate_adapter ; alpha_lora -> O LORA_ALPHA, conforme definido no papel original. Isso é usado para escala (por exemplo, S = alpha_lora/RR).Por exemplo, suponha que desejemos testar o adaptador com conforto de configuração, paralelo, pfeiffer, rr = 64 e testá -lo no conjunto de dados FSC para o modelo AST. Então, o comando a ser executado é:
python3 main.py --data_path ' /path_to_your_dataset ' --is_AST True --dataset_name ' FSC ' --method ' adapter ' --seq_or_par ' parallel ' --reduction_rate_adapter 64 --adapter_type ' Pfeiffer ' --apply_residual False --adapter_block ' conformer ' Se você deseja executar experimentos de aprendizado de poucas fotos, basta definir o sinalizador --is_few_shot_exp como True e especificar o # de amostras por classe --few_shot_samples .
Por favor, entre em contato comigo em: UMBERTOCAPELLAZZO [AT] Gmail [DOT] com qualquer pergunta.
Reconhecemos o apoio da Digital Research Alliance do Canadá (Alliancecan.ca).
@misc{cappellazzo2023parameterefficient,
title={Parameter-Efficient Transfer Learning of Audio Spectrogram Transformers},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti and Mirco Ravanelli},
year={2023},
eprint={2312.03694},
archivePrefix={arXiv},
primaryClass={eess.AS}
}Umberto Cappellazzo, Daniele Falavigna, Alessio Brutti
O artigo foi aceito no Interspeech 2024 . Ele investiga o uso de mistura de especialistas (MOE) para o ajuste fino eficiente de AST. Especificamente, adaptamos o recente método MOE suave à nossa configuração eficiente em parâmetro, onde cada especialista é representado por um módulo adaptador. Chamamos isso de moa suave (mistura suave de adaptadores). O MOA suave alcança a paridade de desempenho com a densa contraparte (densa-MOA) enquanto reduz o custo computacional. Além disso, demonstra desempenho superior sobre o adaptador único tradicional.
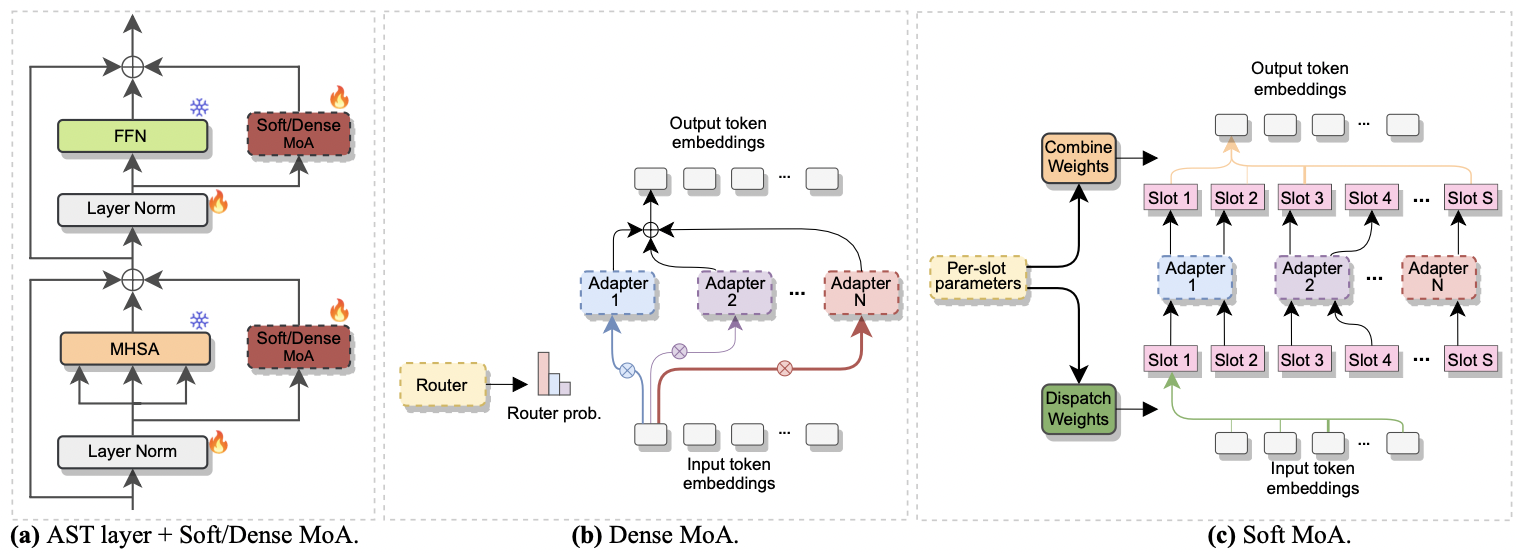 |
|---|
| a) Inserção do adaptador em cada camada AST. b) Denso-MOA. c) MOA suave. |
Executar um experimento com MOA denso e macio é uma brisa. Seguimos o mesmo procedimento que usamos para o papel [1] . Só precisamos definir o parâmetro --method como Dense-MoA ou Soft-MoA e especificar alguns parâmetros ad-hoc:
--reduction_rate_moa : exatamente como para os outros métodos PETL, precisamos especificar a taxa de redução para cada especialista em adaptadores. Quanto maior a taxa de redução, menor a dimensão do gargalo.--adapter_type_moa : configuração pfeiffer ou houlsby .--location_moa : se deve aplicar as camadas MOA macias/densas paralelas aos blocos MHSA ou FFN . If --adapter_type_moa == houlsby, MHSA e FFN são selecionados.--adapter_module_moa : o tipo de adaptador. Apoiamos gargalos e convocações a partir de agora.--num_adapters : quantos adaptadores são usados para cada camada MOA suave/densa. Em nossos experimentos, esse valor varia entre 2 e 15.--num_slots : o número de slots usados no Soft-MOA. Geralmente é definido como 1 ou 2. [ NB : usado apenas em MOA soft]]--normalize : Se para L2 normalizar o vetor de entrada e a matriz phi, conforme proposto no papel MOE suave original (consulte a Seção 2.3, "Normalização"). Conforme declarado no papel, a operação de normalização tem pouco impacto se o tamanho oculto do modelo for pequeno como no nosso caso (por exemplo, 768), portanto não usamos a normalização. [ NB : usado apenas no soft-moa]Por exemplo, suponha que queremos testar o Soft-MOA no conjunto de dados FSC. Além disso, optamos por incluir a camada Soft-MOA apenas nas camadas do MHSA e usamos 7 adaptadores de garrafos. Então, o comando a ser executado é:
python3 main.py --data_path ' /path_to_your_dataset ' --dataset_name ' FSC ' --method ' Soft-MoA ' --reduction_rate_moa 128 --adapter_type_moa ' Pfeiffer ' --location ' MHSA ' --adapter_module_moa ' bottleneck ' --num_adapters 7 --num_slots 1 --normalize False@misc{cappellazzo2024efficient,
title={Efficient Fine-tuning of Audio Spectrogram Transformers via Soft Mixture of Adapters},
author={Umberto Cappellazzo and Daniele Falavigna and Alessio Brutti},
year={2024},
eprint={2402.00828},
archivePrefix={arXiv},
primaryClass={eess.AS}
}

