punica
v1.1.0
(紙)
python examples/tui-multi-lora.py低等級適應(LORA)是為驗證的LLM添加新知識的參數有效方法。儘管驗證的LLM需要100秒的GB存儲空間,但Lora Finetuned模型僅增加了1%的存儲空間和內存開銷。 Punica啟用運行多個Lora Fineted Models的費用,而運行一個模型。
如何?
假設形狀[H1, H2]是驗證模型的W ,Lora添加了兩個小矩陣A形狀[H1, r]和[r, H2]的B在FINETUNED模型上運行輸入x的是y := x @ (W + A@B) ,與y := x@W + x@A@B相同。
當有n Lora型號時,將有A1 , B1 , A2 , B2 ,..., An , Bn 。給定一個輸入批次X := (x1,x2,...,xn) ,將每個lora模型映射到每個lora模型,輸出為Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) 。左側計算驗證模型上的輸入批次。這是非常有效的。由於批處理的效果很強,延遲幾乎與只有一個輸入時相同。
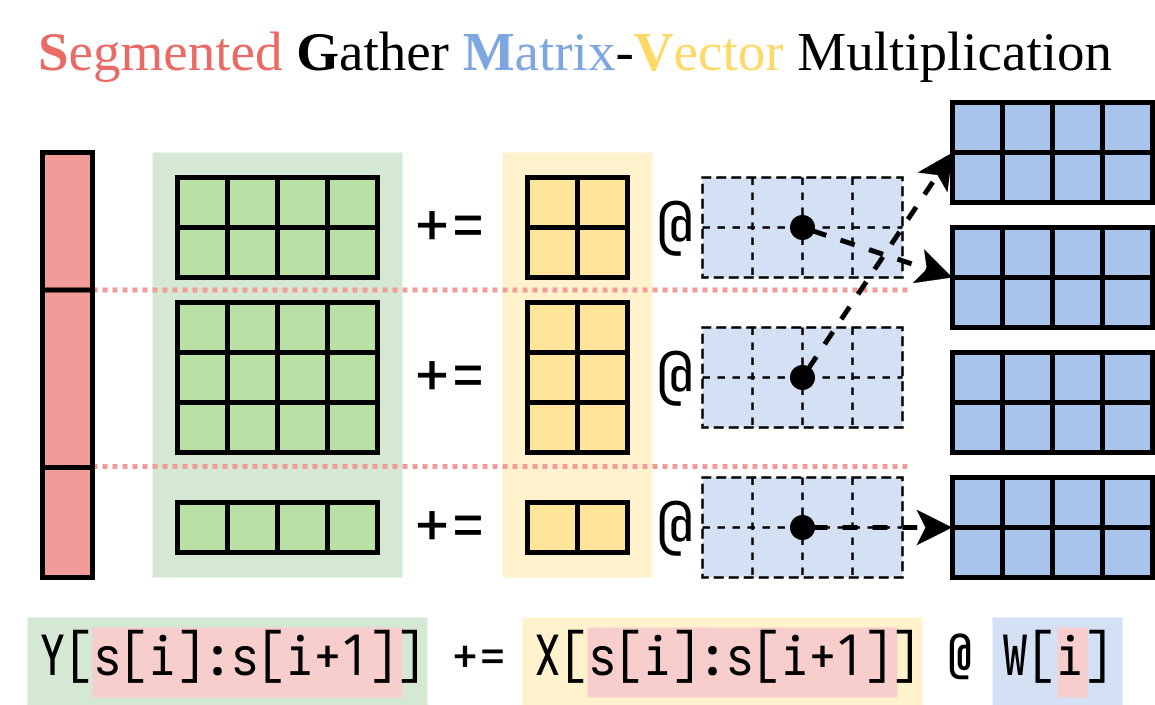
我們找出了一種計算右側(Lora插件)的有效方法。我們將此操作封裝在CUDA內核中,稱為分割的聚集矩陣矢量乘法(SGMV),如下所示。
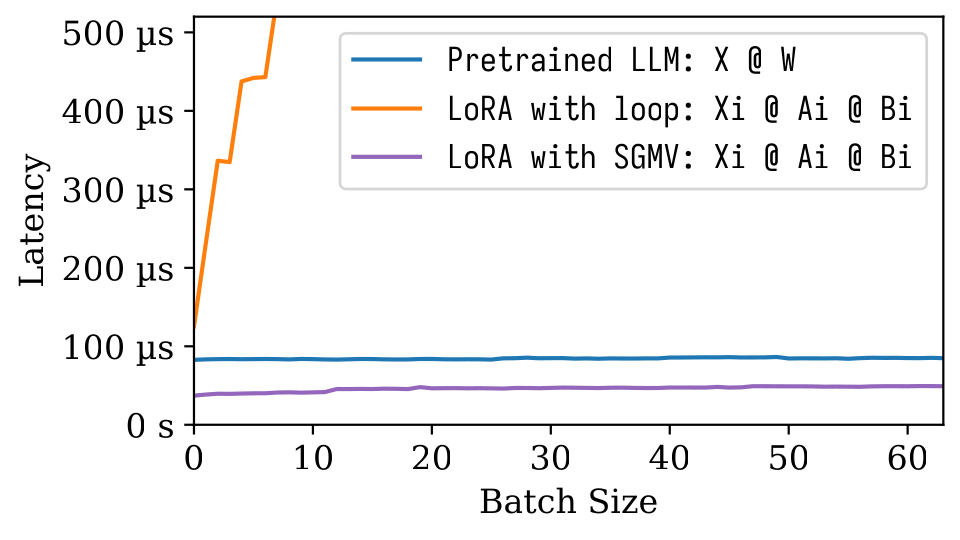
在下面的微型基準圖中,我們可以觀察到預驗證模型的強批量效應。如橙線所示,洛拉的幼稚實施很慢。通過SGMV實施的LORA是有效的,並保留了強大的分批效應。
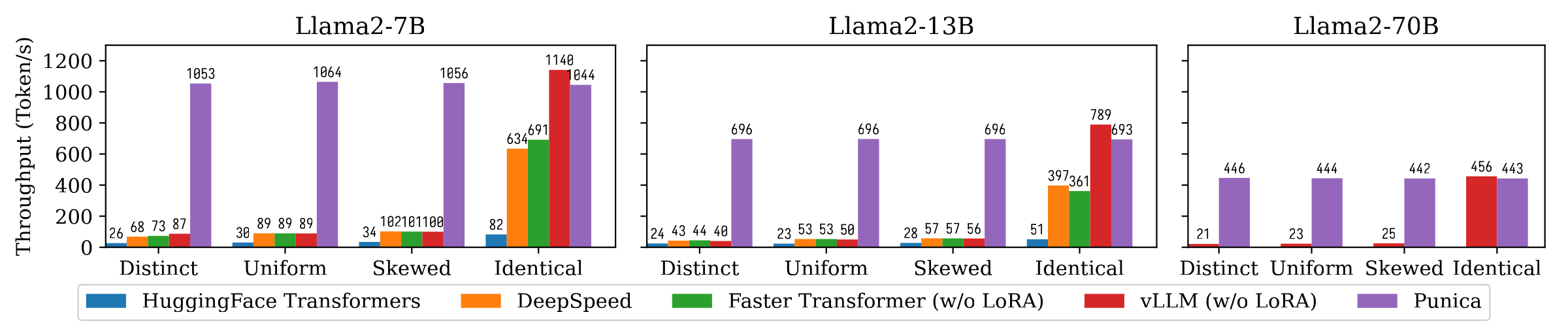
下圖顯示了Punica和其他系統之間的文本生成吞吐量比較,包括擁抱面變壓器,DeepSpeed,ForterTransFormer,VLLM。基準測試考慮了洛拉模型流行的不同設置。獨特的意味著每個請求都是針對不同的洛拉模型。相同的意味著所有請求均適用於同一LORA模型。統一和偏斜介於兩者之間。與最先進的系統相比,Punica達到了12倍吞吐量。
閱讀我們的論文以了解更多信息:Punica:多租戶Lora服務。
您可以從二進制包裝安裝Punica或從源構建。
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . 請參閱上面的演示。
請參閱examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

