punica
v1.1.0
(kertas)
python examples/tui-multi-lora.pyAdapasi peringkat rendah (LORA) adalah cara parameter yang efisien untuk menambahkan pengetahuan baru ke LLM pretrained. Meskipun LLM pretrained mengambil 100 -an GB Storage, model Lora Finetuned hanya menambahkan 1% penyimpanan dan overhead memori. Punica memungkinkan menjalankan beberapa model Lora Finetuned dengan biaya menjalankannya.
Bagaimana?
Dengan asumsi W dari bentuk [H1, H2] adalah berat model pretrained, Lora menambahkan dua matriks kecil A bentuk [H1, r] dan B [r, H2] . Menjalankan input x pada model finetuned adalah y := x @ (W + A@B) , yang sama dengan y := x@W + x@A@B .
Ketika ada model n lora, akan ada A1 , B1 , A2 , B2 , ..., An , Bn . Diberikan batch input X := (x1,x2,...,xn) yang memetakan untuk setiap model lora, outputnya adalah Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) . Sisi kiri menghitung batch input pada model pretrained. Itu cukup efisien. Latensi hampir sama dengan ketika hanya ada satu input, berkat efek batching yang kuat.
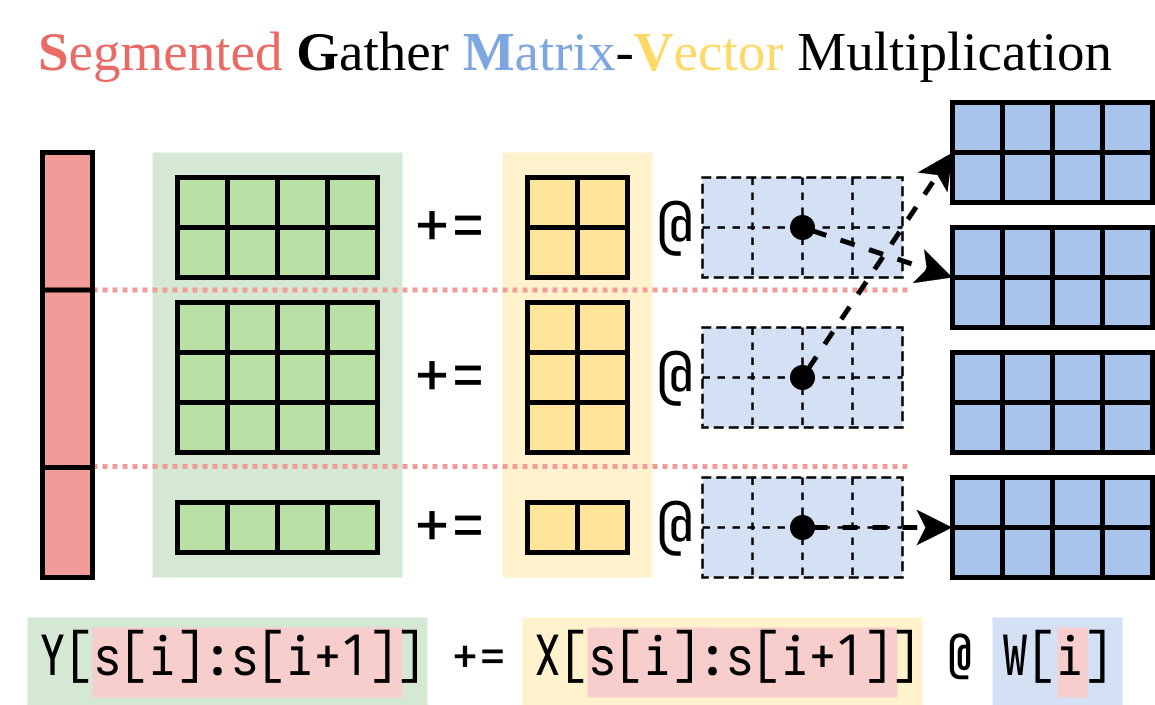
Kami menemukan cara yang efisien untuk menghitung sisi kanan (Lora Addon). Kami merangkum operasi ini dalam kernel CUDA, yang disebut pengumpulan kumpulan matriks-vektor yang tersegmentasi (SGMV), seperti yang diilustrasikan di bawah ini.
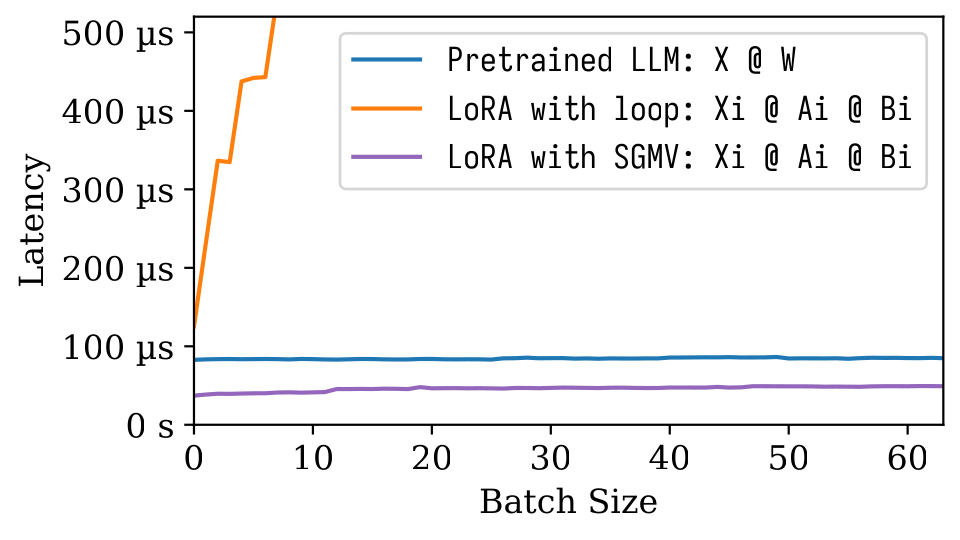
Dalam gambar microbenchmark berikut, kita dapat mengamati efek batching yang kuat dari model pretrained. Implementasi LORA yang naif lambat, seperti yang digambarkan dalam garis oranye. Lora yang diimplementasikan melalui SGMV efisien dan mempertahankan efek batching yang kuat.
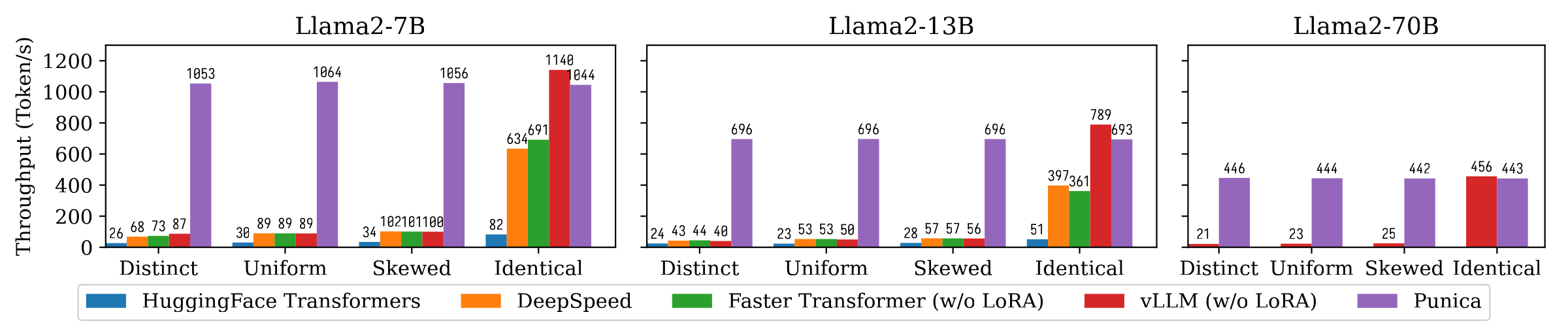
Gambar berikut menunjukkan perbandingan throughput pembuatan teks antara Punica dan sistem lain, termasuk transformator huggingface, Deepspeed, FasterTransformer, VLLM. Benchmark mempertimbangkan berbagai pengaturan popularitas model Lora. Berbeda berarti bahwa setiap permintaan adalah untuk model LORA yang berbeda. Identik berarti bahwa semua permintaan adalah untuk model LORA yang sama. Seragam dan miring ada di antaranya. Punica mencapai throughput 12x dibandingkan dengan sistem canggih.
Baca makalah kami untuk memahami lebih lanjut: Punica: Multi-Tenant Lora Serving.
Anda dapat menginstal Punica dari paket biner atau membangun dari sumber.
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . Lihat demo di atas.
Lihat examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

