punica
v1.1.0
(papel)
python examples/tui-multi-lora.pyA adaptação de baixa classificação (LORA) é uma maneira eficiente de parâmetro de adicionar novos conhecimentos a um LLM pré -traçado. Embora o LLM pré -treinado leve 100s de armazenamento GB, um modelo Lora Finetuned adiciona apenas 1% de armazenamento e sobrecarga de memória. A Punica permite a execução de vários modelos Lora Finetuned ao custo da execução de um.
Como?
Supondo que W da forma [H1, H2] seja o peso do modelo pré -treinado, Lora adiciona duas pequenas matrizes A de forma [H1, r] e B de [r, H2] . A execução de uma entrada x no modelo Finetuned seria y := x @ (W + A@B) , que é o mesmo que y := x@W + x@A@B .
Quando houver n modelos lora, haverá A1 , B1 , A2 , B2 , ..., An , Bn . Dado um lote de entrada X := (x1,x2,...,xn) que mapeia para cada modelo LORA, a saída é Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) . O lado esquerdo calcula o lote de entrada no modelo pré-treinado. É bastante eficiente. A latência é quase a mesma de quando há apenas uma entrada, graças ao forte efeito de lotes.
Descobrimos uma maneira eficiente de calcular o lado direito (o addon Lora). Encapsamos essa operação em um kernel Cuda, chamado de multiplicação de vetor matriz segmentado (SGMV), conforme ilustrado abaixo.
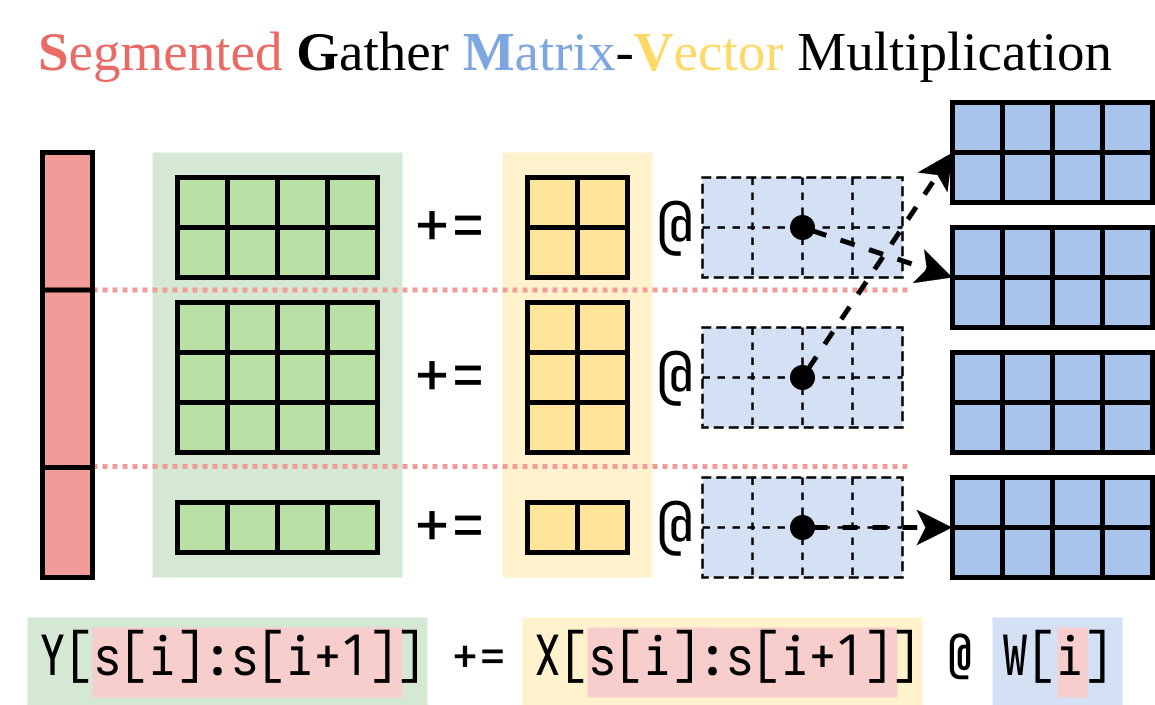
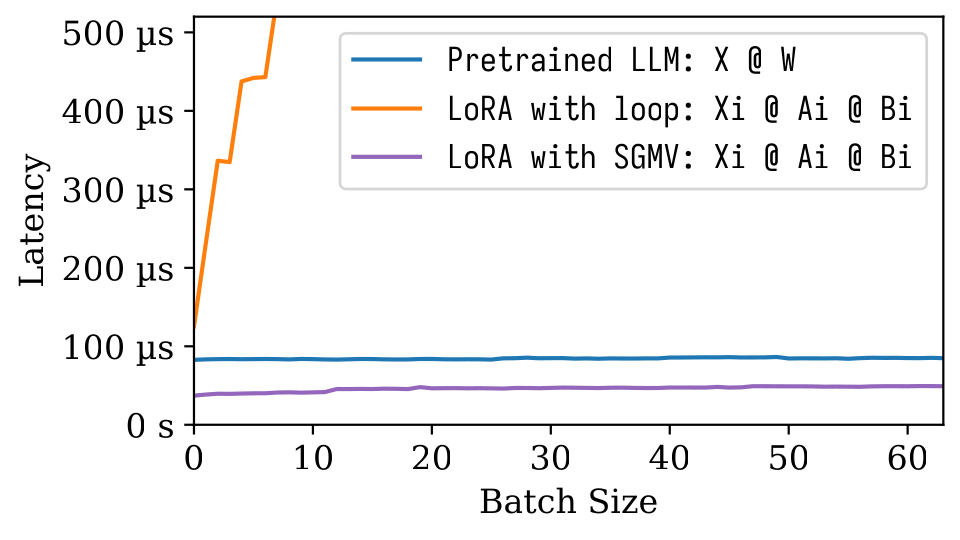
Na figura de Microbenchmark seguinte, podemos observar o forte efeito de lote do modelo pré -treinado. A implementação ingênua de Lora é lenta, conforme mostrado na linha laranja. A LORA implementada via SGMV é eficiente e preserva o forte efeito de lotes.
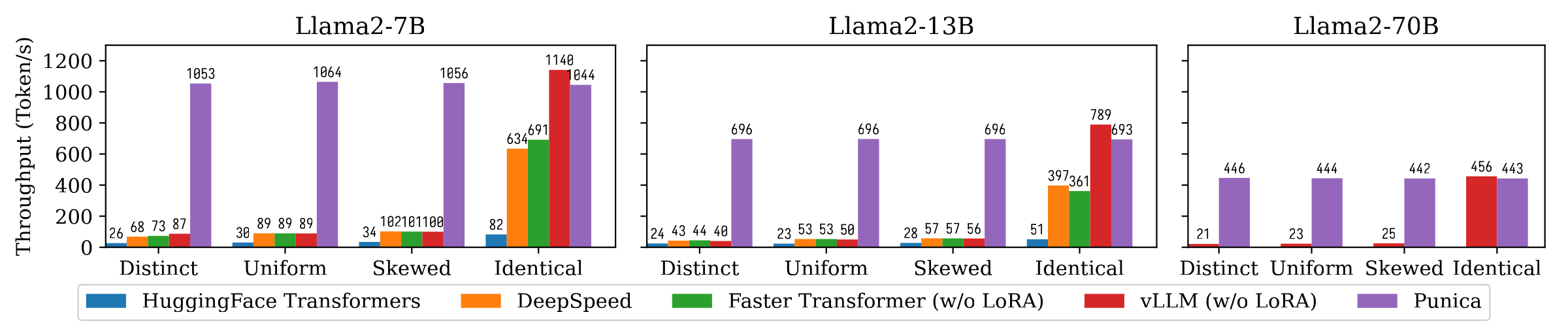
A figura a seguir mostra a comparação de taxa de transferência de geração de texto entre Punica e outros sistemas, incluindo Transformadores Huggingface, DeepSpeed, Fastertransformer, VLLM. O benchmark considera diferentes configurações da popularidade do modelo de Lora. Distinto significa que cada solicitação é para um modelo LORA diferente. Idêntico significa que todas as solicitações são para o mesmo modelo Lora. Uniforme e distorcido estão no meio. A Punica atinge a taxa de transferência de 12x em comparação com os sistemas de última geração.
Leia nosso artigo para entender mais: Punica: porções de Lora Multi-Tenant.
Você pode instalar o punica a partir do pacote binário ou construir a partir da fonte.
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . Veja a demonstração acima.
Veja examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

