punica
v1.1.0
(Papier)
python examples/tui-multi-lora.pyLORA -Anpassungsanpassung (LORA) ist ein effizienter Parameter, um einem vorbereiteten LLM neues Wissen hinzuzufügen. Obwohl die vorab vorbereitete LLM 100s GB -Speicher aufnimmt, fügt ein LORA -Finetuned -Modell nur 1% Speicher- und Speicheraufwand hinzu. Punica ermöglicht es, mehrere Lora -Finetuned -Modelle auf Kosten des Ausführens eines auszuführen.
Wie?
Unter der Annahme, dass W von Form [H1, H2] das Gewicht des vorbereiteten Modells ist, fügt Lora zwei kleine Matrizen A mit Form [H1, r] und B von [r, H2] hinzu. Ausführen eines Eingangs x auf dem finetunierten Modell wäre y := x @ (W + A@B) , das ist das gleiche wie y := x@W + x@A@B .
Wenn es n -Lora -Modelle gibt, wird es A1 , B1 , A2 , B2 , ..., An , Bn geben. Bei einem Eingangs -Stapel X := (x1,x2,...,xn) das jedes Lora -Modell kartiert, ist die Ausgabe Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) . Die linke Seite berechnet die Eingangsfigur des vorgenannten Modells. Es ist ziemlich effizient. Die Latenz ist fast die gleiche wie bei nur einem Eingang, dank des starken Chargeneffekts.
Wir haben einen effizienten Weg gefunden, um die rechte Seite (das Lora-Addon) zu berechnen. Wir verkapulieren diesen Vorgang in einem CUDA-Kernel, das als segmentierte Sammel-Matrixvektor-Multiplikation (SGMV) bezeichnet wird, wie unten dargestellt.
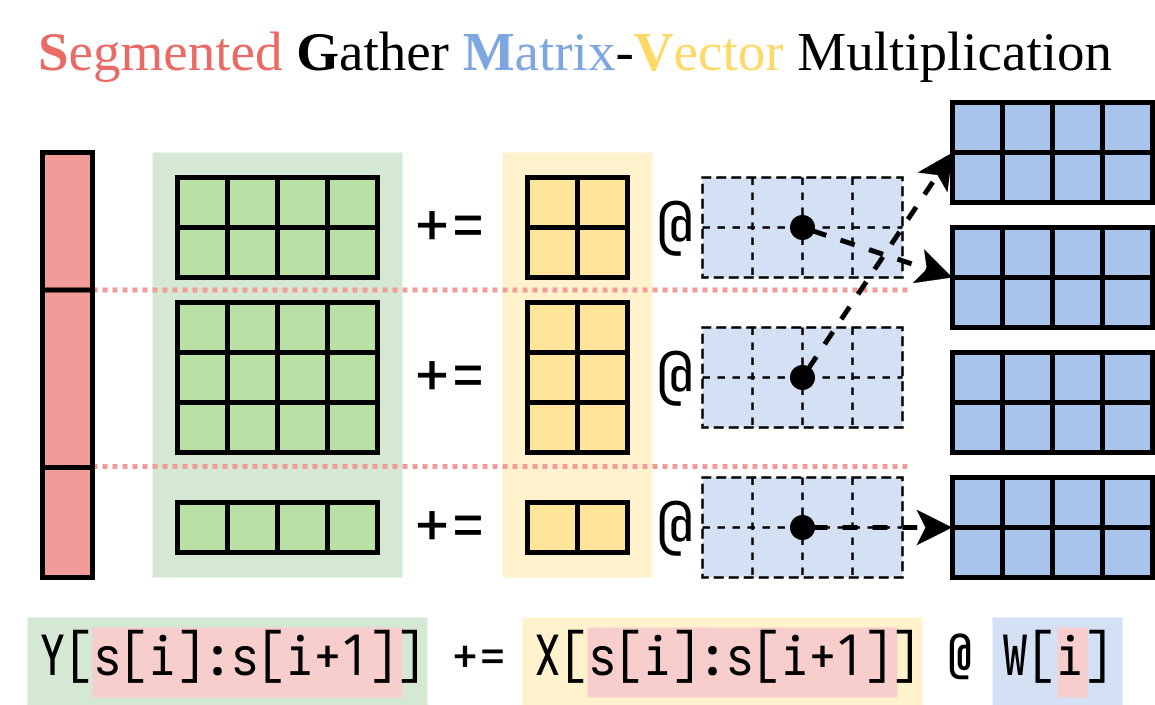
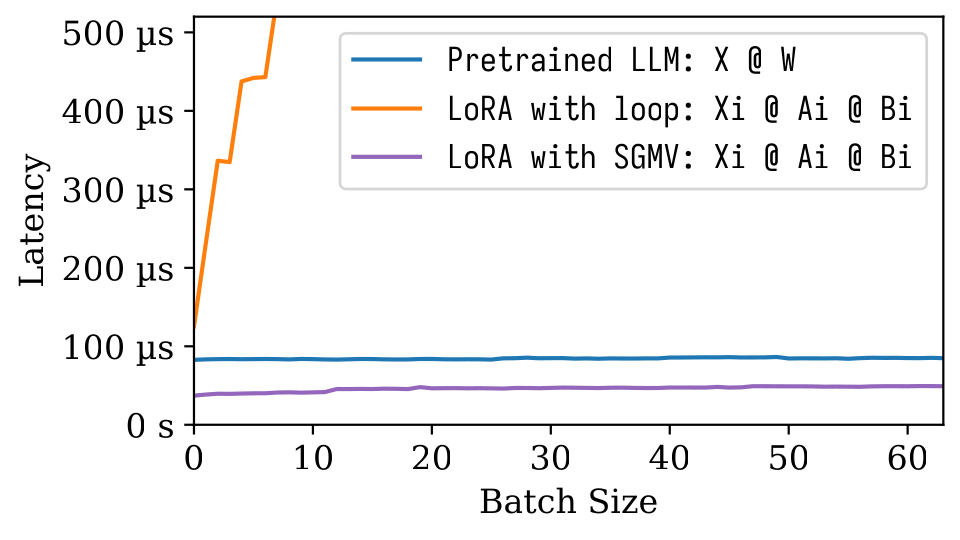
In der folgenden Mikrobenchmark -Zahl können wir den starken Chargeneffekt des vorbereiteten Modells beobachten. Die naive Implementierung von Lora ist langsam, wie in der Orangenlinie dargestellt. LORA über SGMV implementiert ist effizient und bewahrt den starken Chargeneffekt.
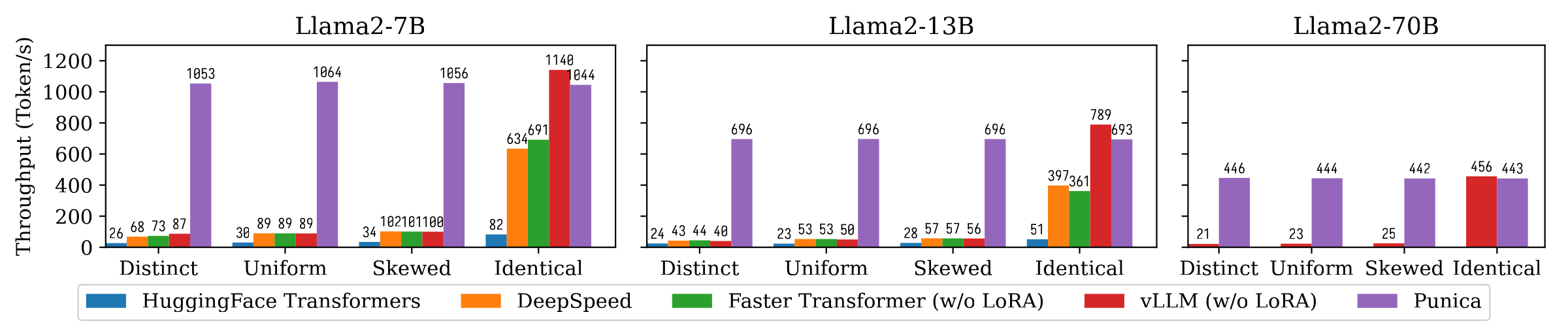
Die folgende Abbildung zeigt den Durchsatzvergleich zwischen Punica und anderen Systemen, einschließlich der Transformatoren von Huggingface, Deepspeed, FasterTransformer, VLLM. Der Benchmark berücksichtigt verschiedene Einstellungen der Lora -Modellpopularität. Verschiedene bedeutet, dass jede Anfrage für ein anderes LORA -Modell gilt. Identische bedeutet, dass alle Anfragen für dasselbe Lora -Modell gelten. Uniform und verzerrt sind dazwischen. Punica erreicht im Vergleich zu hochmodernen Systemen den 12x-Durchsatz.
Lesen Sie unser Papier, um mehr zu verstehen: Punica: Multi-Tenant Lora Serving.
Sie können Punica aus dem Binärpaket installieren oder aus der Quelle erstellen.
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . Siehe die Demo oben.
Siehe examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

