punica
v1.1.0
(papier)
python examples/tui-multi-lora.pyL'adaptation à faible rang (LORA) est un moyen efficace par des paramètres d'ajouter de nouvelles connaissances à un LLM pré-entraîné. Bien que le LLM pré-entraîné prenne 100s de stockage GB, un modèle LORA Finetuned n'ajoute que 1% de stockage et de surcharge de mémoire. Punica permet d'exécuter plusieurs modèles LORA FineTened au prix de l'exécution d'un.
Comment?
En supposant que W de forme [H1, H2] est le poids du modèle pré-entraîné, LORA ajoute deux petites matrices A de forme [H1, r] et B de [r, H2] . L'exécution d'une entrée x sur le modèle Finetuned serait y := x @ (W + A@B) , qui est la même que y := x@W + x@A@B .
Lorsqu'il y a des modèles n LORA, il y aura A1 , B1 , A2 , B2 , ..., An , Bn . Étant donné un lot d'entrée X := (x1,x2,...,xn) qui mappe à chaque modèle LORA, la sortie est Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) . Le côté gauche calcule le lot d'entrée sur le modèle pré-entraîné. C'est assez efficace. La latence est presque la même que lorsqu'il n'y a qu'une seule entrée, grâce au fort effet de lot.
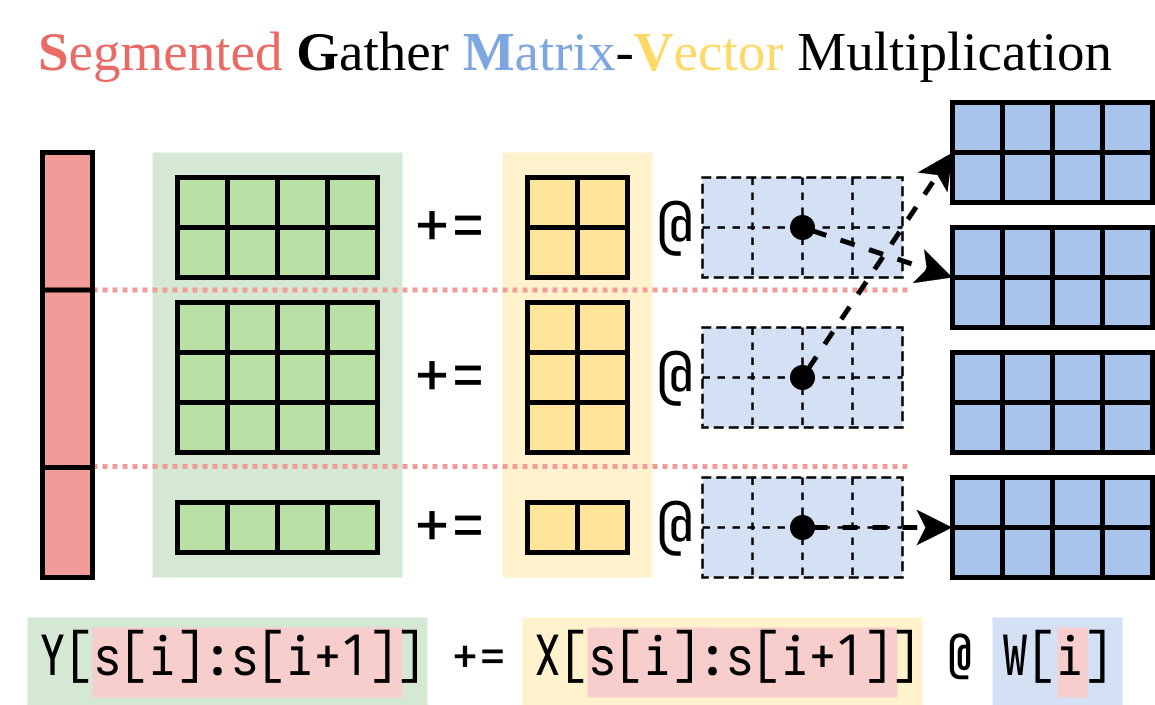
Nous avons trouvé un moyen efficace de calculer le côté droit (l'addon LORA). Nous encapsulons cette opération dans un noyau CUDA, appelé multiplication de vecteur matrice-vecteur segmenté (SGMV), comme illustré ci-dessous.
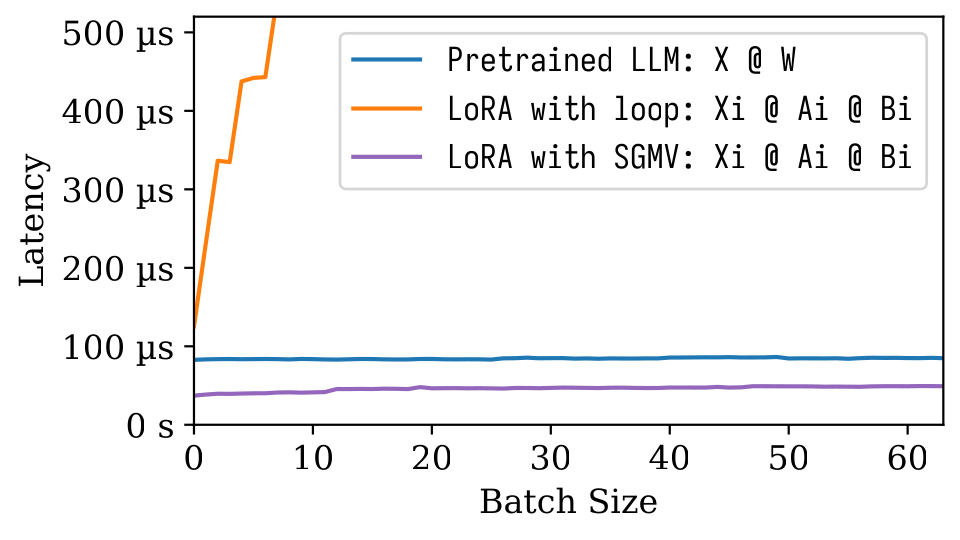
Dans la figure du microbenchmarché suivant, nous pouvons observer le fort effet de lots du modèle pré-entraîné. La mise en œuvre naïve de LORA est lente, comme illustré dans la ligne orange. LORA implémentée via SGMV est efficace et préserve le fort effet de lots.
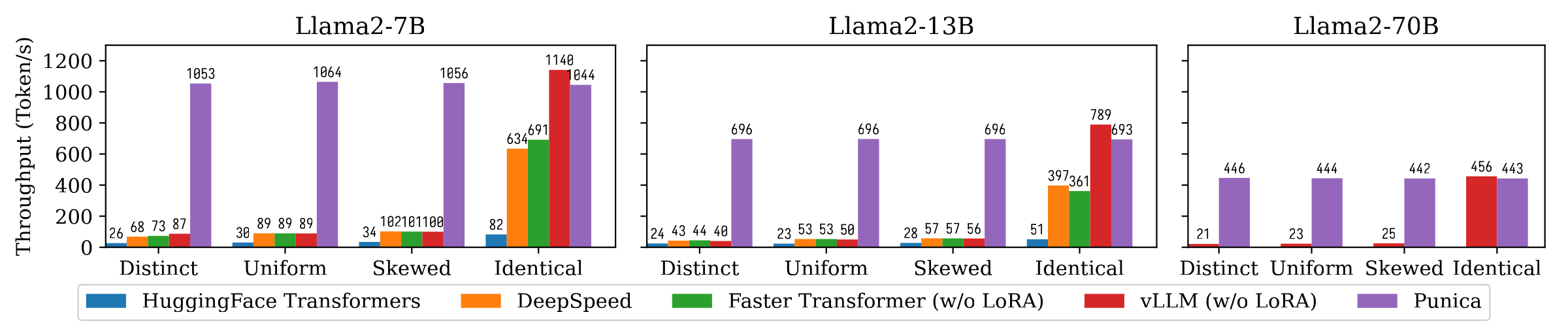
La figure suivante montre la comparaison du débit de génération de texte entre Punica et d'autres systèmes, notamment les transformateurs à étreindre, Deeppeed, FasterTransformateur, VLLM. La référence considère les différents paramètres de la popularité du modèle LORA. Un distinct signifie que chaque demande concerne un modèle LORA différent. Identique signifie que toutes les demandes sont pour le même modèle LORA. Uniforme et biaisé sont entre les deux. Punica atteint un débit 12x par rapport aux systèmes de pointe.
Lisez notre article pour en savoir plus: Punica: Service multi-locataire Lora.
Vous pouvez installer Punica à partir du package binaire ou construire à partir de la source.
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . Voir la démo ci-dessus.
Voir examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

