punica
v1.1.0
(종이)
python examples/tui-multi-lora.pyLORA (Low Rank) 적응 (LORA)은 새벽에 새로 지식이있는 LLM에 새로운 지식을 추가하는 매개 변수 효율적인 방법입니다. 사전 배치 된 LLM은 100 대의 GB 스토리지를 사용하지만 LORA FINETUNED 모델은 1%의 스토리지 및 메모리 오버 헤드 만 추가합니다. Punica를 사용하면 달리기 비용으로 여러 Lora Finetuned 모델을 실행할 수 있습니다.
어떻게?
w [H1, H2] 의 W B 사전 치료 된 모델의 중량이라고 가정하면 Lora는 [H1, r] 및 [r, H2] 의 두 개의 작은 행렬 A 추가합니다. FinetUned 모델에서 입력 x 실행하면 y := x @ (W + A@B) 이며 y := x@W + x@A@B 와 동일합니다.
n LORA 모델이 있으면 A1 , B1 , A2 , B2 , ..., An , Bn 있습니다. 각 LORA 모델에 맵핑하는 입력 배치 X := (x1,x2,...,xn) 을 감안할 때, 출력은 Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) 입니다. 왼쪽은 사전에 입력 된 모델에서 입력 배치를 계산합니다. 매우 효율적입니다. 대기 시간은 강한 배치 효과 덕분에 입력이 하나만있을 때와 거의 동일합니다.
우리는 오른쪽을 계산하는 효율적인 방법을 알아 냈습니다 (Lora Addon). 아래 그림과 같이 SGMV (Segmented Gather Matrix-Vector Multiplication)라는 Cuda 커널 에서이 작업을 캡슐화합니다.
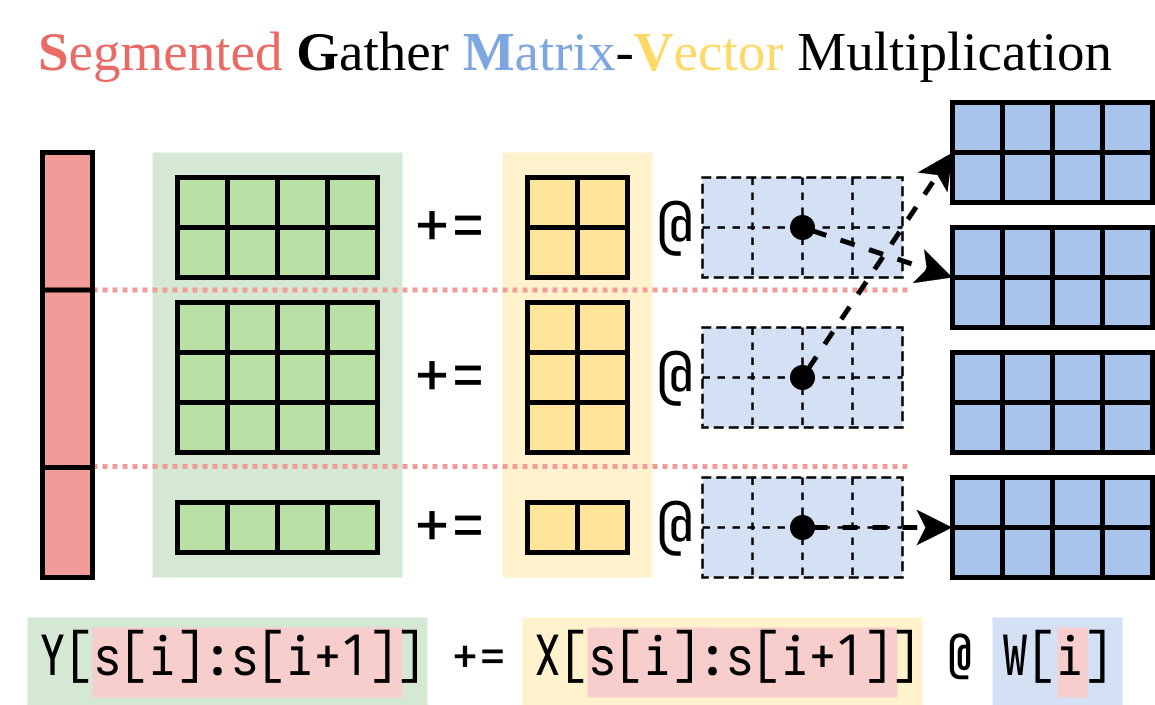
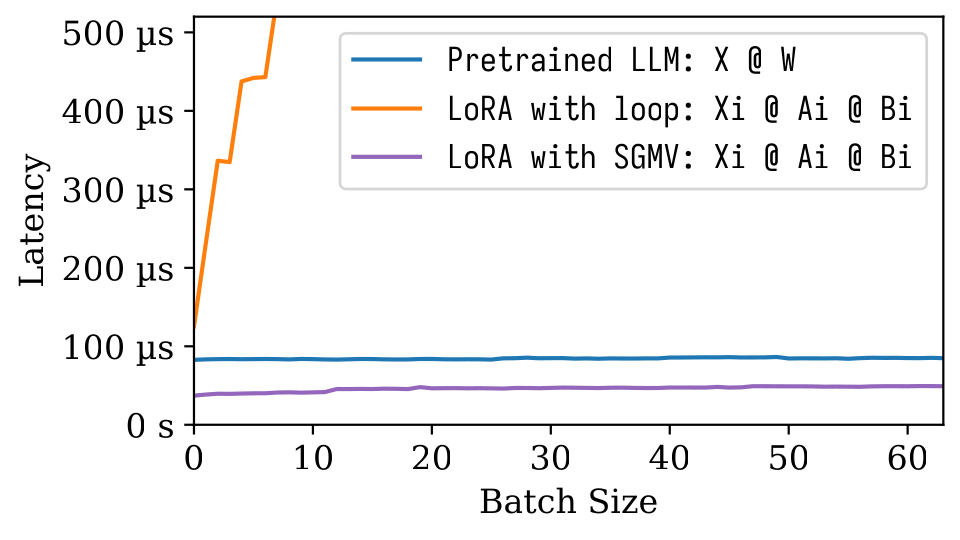
다음 MicroBenchmark 그림에서는 사전에 걸린 모델의 강력한 배치 효과를 관찰 할 수 있습니다. 오렌지 라인에 묘사 된 것처럼 LORA의 순진한 구현은 느립니다. SGMV를 통해 구현 된 LORA는 효율적이며 강력한 배치 효과를 보존합니다.
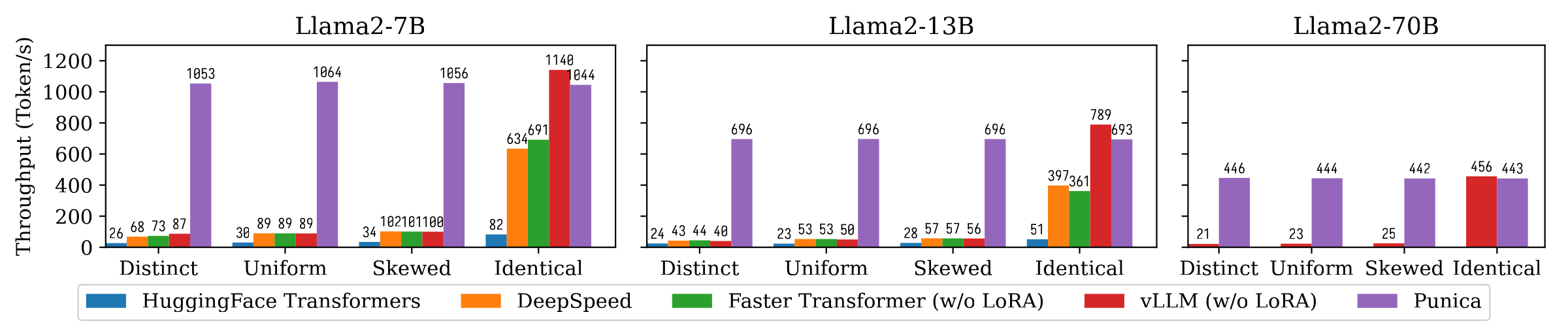
다음 그림은 Punica와 Huggingface Transformers, DeepSpeed, FasterTransformer, VLLM을 포함한 다른 시스템 간의 텍스트 생성 처리량 비교를 보여줍니다. 벤치 마크는 LORA 모델 인기의 다양한 설정을 고려합니다. 뚜렷한 것은 각 요청이 다른 LORA 모델에 대한 것임을 의미합니다. 동일한 것은 모든 요청이 동일한 LORA 모델에 대한 것임을 의미합니다. 균일 하고 비뚤어진 것은 그 사이에 있습니다. Punica는 최첨단 시스템에 비해 12 배의 처리량을 달성합니다.
더 이해하려면 논문을 읽으십시오 : Punica : Multi-Tenant Lora Serving.
이진 패키지에서 Punica를 설치하거나 소스에서 빌드 할 수 있습니다.
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . 위의 데모를 참조하십시오.
examples/finetune/ 참조하십시오.
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

