punica
v1.1.0
(бумага)
python examples/tui-multi-lora.pyАдаптация с низким рангом (LORA) является эффективным параметром, чтобы добавить новые знания к предварительному LLM. Несмотря на то, что предварительному LLM занимает 100 -е годы GB хранилища, модель Lora Cenetuned только добавляет 1% накладных расходов на память и память. Punica позволяет запускать несколько моделей Lora Cenetuned за счет работы.
Как?
Предполагая, что W формы [H1, H2] является весом предварительной модели, Лора добавляет две маленькие матрицы A Shape [H1, r] и B [r, H2] . Запуск ввода x на современной модели будет y := x @ (W + A@B) , что такое же, как y := x@W + x@A@B .
Когда будут модели n Lora, будет A1 , B1 , A2 , B2 , ..., An , Bn . Учитывая входную партию X := (x1,x2,...,xn) , которая отображает каждую модель LORA, выход Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) . Левая сторона вычисляет входную партию на предварительном модели. Это довольно эффективно. Задержка почти такая же, как и когда есть только один вход, благодаря сильным эффектам партии.
Мы выяснили эффективный способ вычисления правой стороны (аддон Лора). Мы инкапсулируем эту операцию в ядро CUDA, называемое сегментированным умножением матричного вектора (SGMV), как показано ниже.
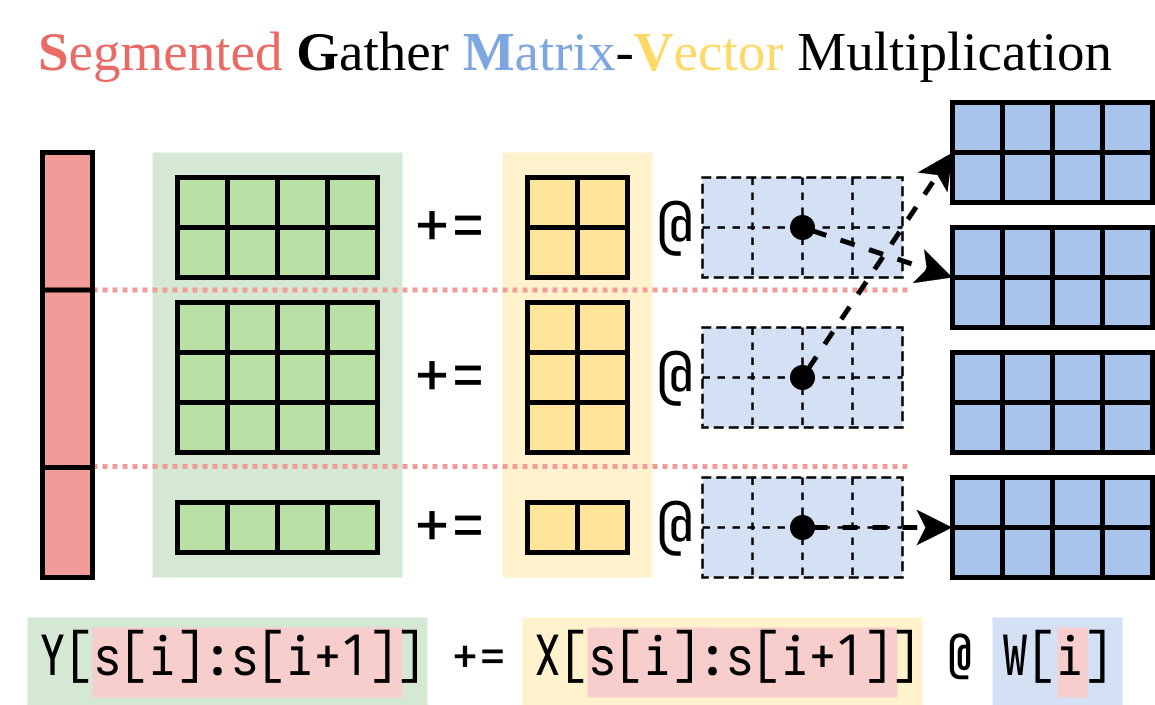
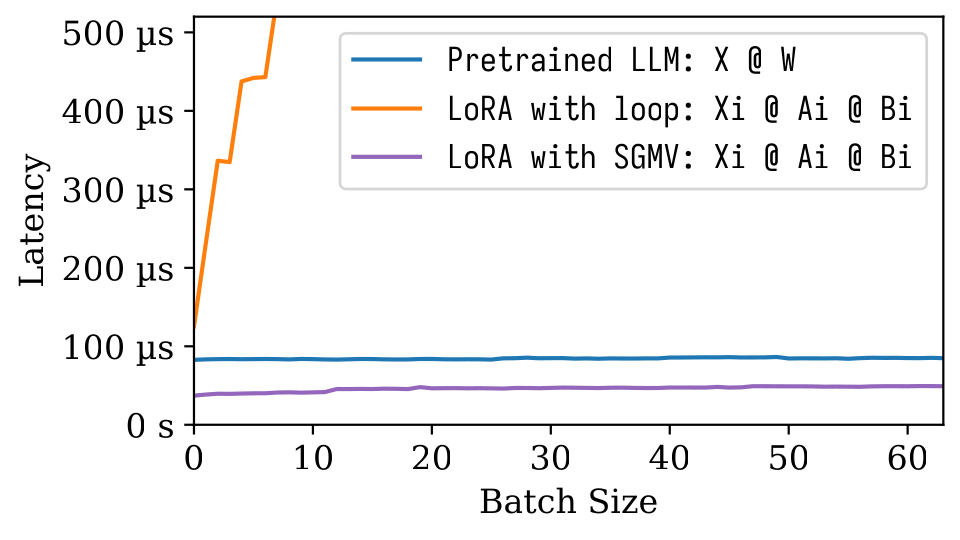
На следующей фигуре Microbenchmark мы можем наблюдать сильный пакетный эффект предварительно предварительной модели. Наивная реализация Лоры медленная, как изображено на апельсиновой линии. LORA, реализованная через SGMV, является эффективной и сохраняет сильный эффект партии.
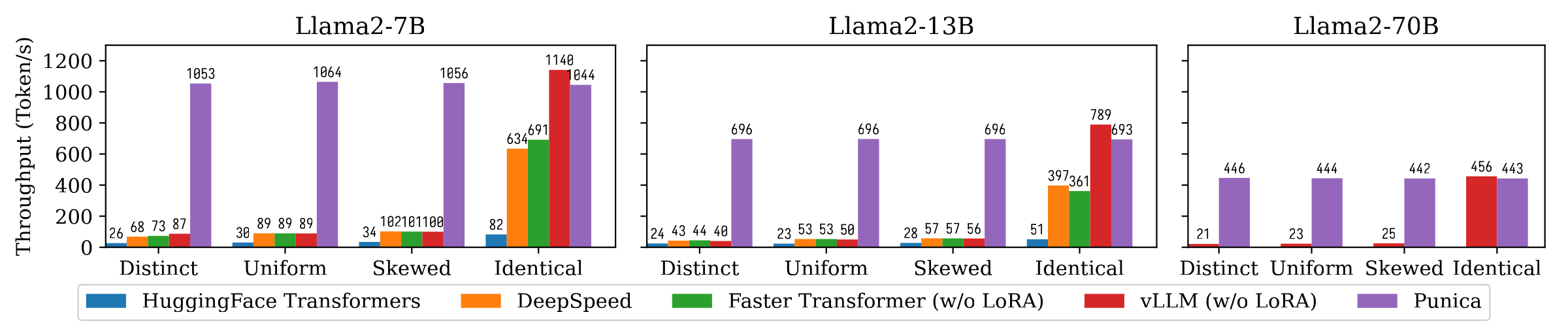
На следующем рисунке показано сравнение пропускной способности генерации текста между Пуникой и другими системами, включая трансформаторы Huggingface, Deepspeed, Feartransformer, VLLM. Трингм рассматривает различные настройки популярности модели LORA. Различание означает, что каждый запрос предназначен для другой модели LORA. Идентичные означает, что все запросы предназначены для одной и той же модели LORA. Разнообразная и перекошенная между ними между ними. Пуника достигает 12-кратной пропускной способности по сравнению с современными системами.
Прочитайте нашу статью, чтобы понять больше: Punica: Multainant Lora Foring.
Вы можете установить Punica из двоичного пакета или построить из источника.
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . Смотрите демонстрацию выше.
См examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

