punica
v1.1.0
(ورق)
python examples/tui-multi-lora.pyيعد تكييف الترتيب المنخفض (LORA) وسيلة فعالة للمعلمة لإضافة معرفة جديدة إلى LLM PRETRAING. على الرغم من أن LLM PRETRAINED يأخذ 100s من تخزين GB ، فإن طراز Lora المحدد لا يضيف إلا 1 ٪ تخزين وذاكرة النفقات العامة. تتيح Bunica تشغيل نماذج Lora Finetuned متعددة على حساب تشغيل واحد.
كيف؟
على افتراض W من الشكل [H1, H2] هو وزن النموذج المسبق ، يضيف Lora مصفوفين صغيرتين A الشكل [H1, r] و B من [r, H2] . سيكون تشغيل إدخال x على النموذج المحدد y := x @ (W + A@B) ، وهو نفس y := x@W + x@A@B .
عندما يكون هناك نماذج n Lora ، سيكون هناك A1 و B1 و A2 و B2 و ... An ، Bn . بالنظر إلى دفعة إدخال X := (x1,x2,...,xn) التي تُخطط لكل نموذج lora ، يكون الإخراج Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) . يحسب الجانب الأيسر دفعة الإدخال على النموذج المسبق. إنه فعال للغاية. يكون الكمون هو نفسه تقريبًا كما هو الحال عندما يكون هناك مدخل واحد فقط ، وذلك بفضل تأثير الجليد القوي.
لقد اكتشفنا طريقة فعالة لحساب الجانب الأيمن (The Lora Addon). نحن نغلف هذه العملية في kernel CUDA ، تسمى مضاعفة المصفوفة المصفوفة المجزأة (SGMV) ، كما هو موضح أدناه.
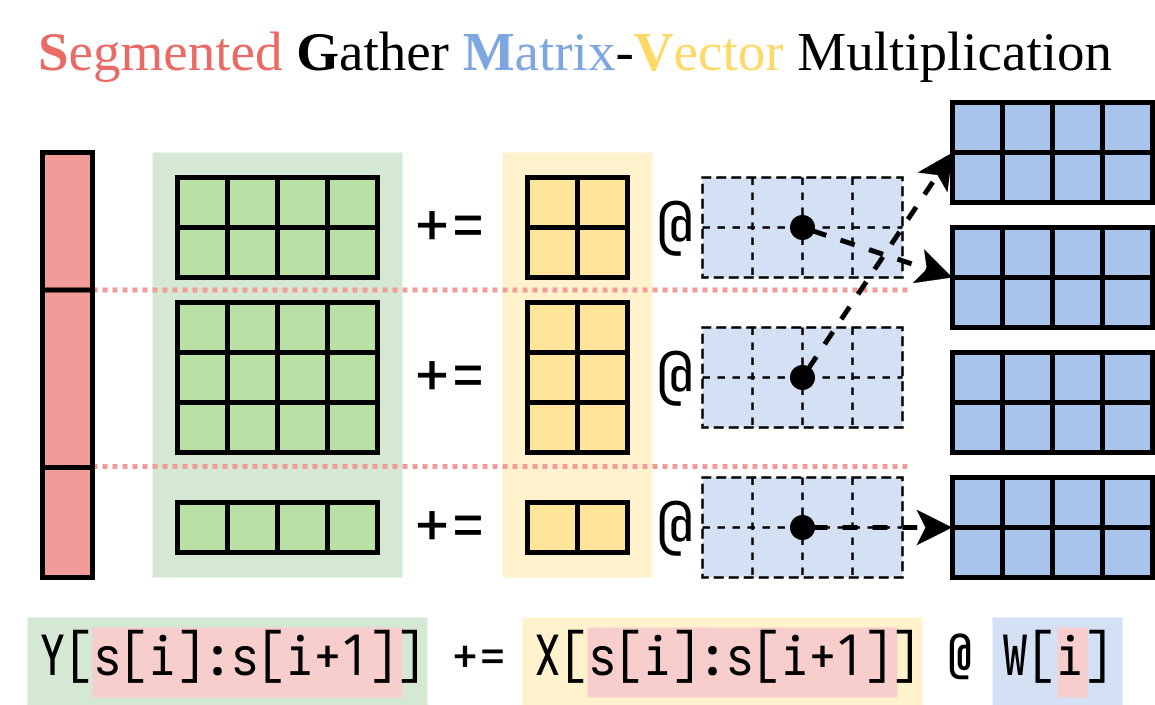
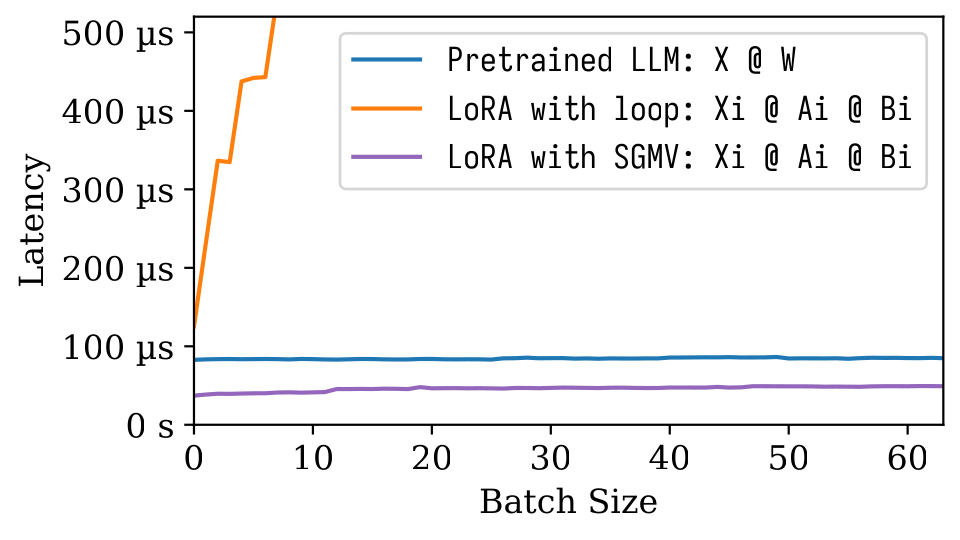
في الرقم التالي من Microbenchmark ، يمكننا ملاحظة التأثير القوي للتجميع للنموذج المسبق. التنفيذ الساذج لـ Lora بطيء ، كما هو موضح في الخط البرتقالي. تم تنفيذ Lora عبر SGMV فعال ويحافظ على تأثير الضغط القوي.
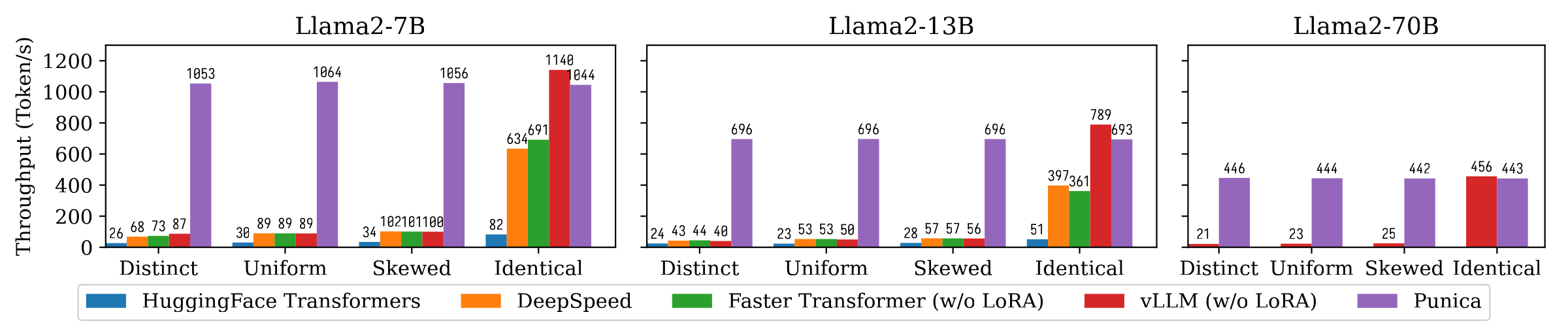
يوضح الشكل التالي مقارنة إنتاجات توليد النص بين Punica والأنظمة الأخرى ، بما في ذلك محولات Huggingface و Deepspeed و FasterTransformer و VLLM. يعتبر المعيار إعدادات مختلفة من شعبية طراز Lora. مميز يعني أن كل طلب هو لنموذج لورا مختلف. وسيلة متطابقة أن جميع الطلبات هي لنفس نموذج لورا. موحدة ومتذبذب بينهما. تحقق بونيكا إنتاجية 12x مقارنة بالأنظمة الحديثة.
اقرأ ورقتنا لفهم المزيد: بونيكا: خدمة متعددة المستأجرين لورا.
يمكنك تثبيت Punica من الحزمة الثنائية أو البناء من المصدر.
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . انظر العرض التوضيحي أعلاه.
انظر examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

