punica
v1.1.0
(papel)
python examples/tui-multi-lora.pyLa adaptación de bajo rango (LORA) es una forma eficiente de parámetros de agregar nuevos conocimientos a una LLM previa a la aparición. Aunque el LLM previamente prostrado toma 100s de almacenamiento GB, un modelo Finetuned Lora solo agrega 1% de almacenamiento y sobrecarga de memoria. Punica permite ejecutar múltiples modelos Finetuned Lora a costa de ejecutar uno.
¿Cómo?
Suponiendo que W de forma [H1, H2] es el peso del modelo previamente pretrados, Lora agrega dos pequeñas matrices A de forma [H1, r] y B de [r, H2] . Ejecutar una entrada x en el modelo Finetuned sería y := x @ (W + A@B) , que es lo mismo que y := x@W + x@A@B .
Cuando hay modelos n lora, habrá A1 , B1 , A2 , B2 , ..., An , Bn . Dado un lote de entrada X := (x1,x2,...,xn) que se asigna a cada modelo lora, la salida es Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) . El lado izquierdo calcula el lote de entrada en el modelo de petróleo. Es bastante eficiente. La latencia es casi la misma que cuando solo hay una entrada, gracias al fuerte efecto de lotes.
Descubrimos una forma eficiente de calcular el lado derecho (el complemento Lora). Encapsulamos esta operación en un núcleo CUDA, llamado multiplicación de vector de matriz de recolección segmentada (SGMV), como se ilustra a continuación.
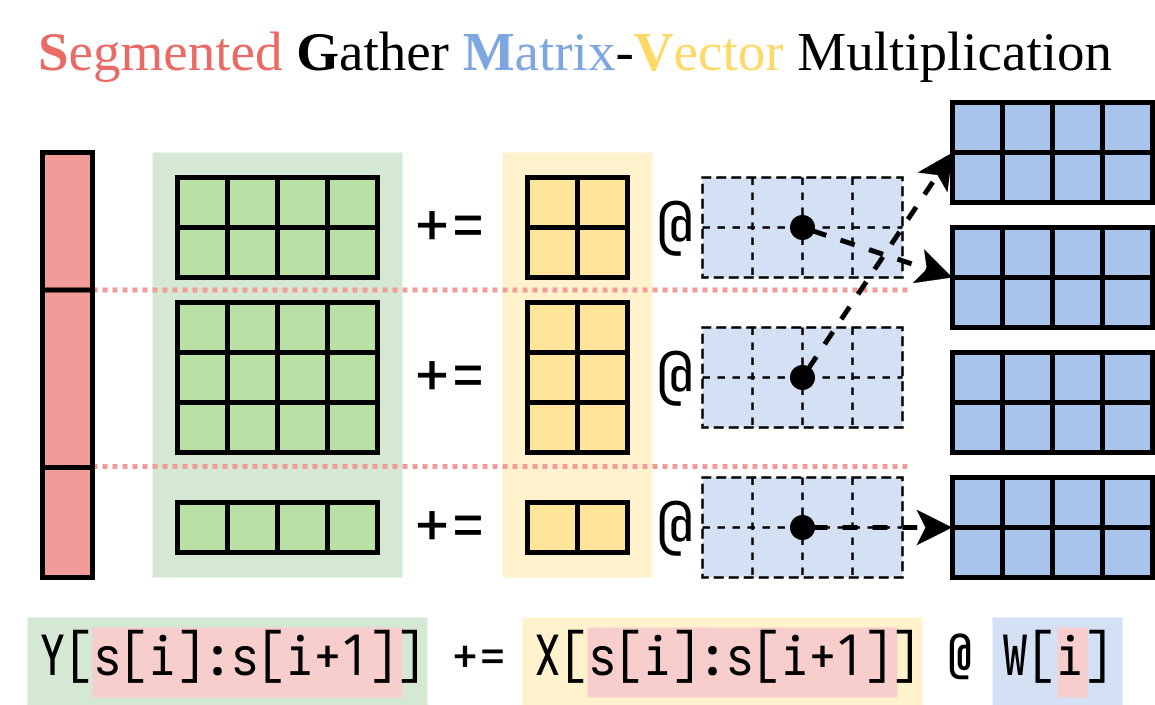
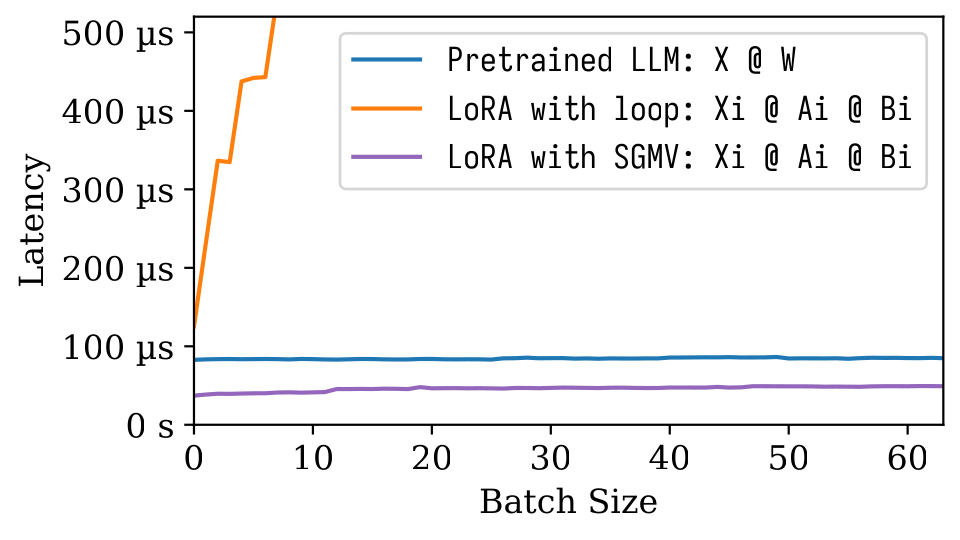
En la siguiente figura de Microbenchmark, podemos observar el fuerte efecto de lotes del modelo previo a la aparición. La implementación ingenua de Lora es lenta, como se muestra en la línea naranja. Lora implementada a través de SGMV es eficiente y conserva el fuerte efecto de lotes.
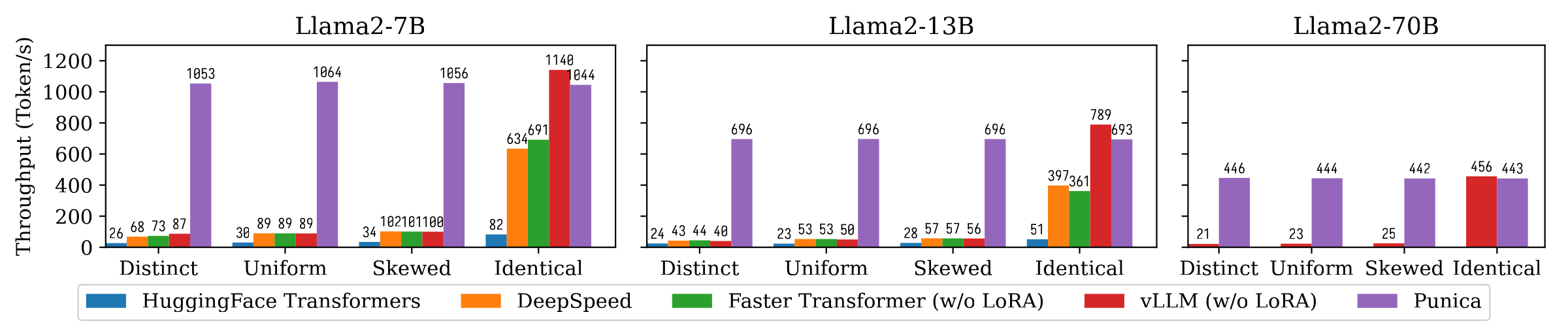
La siguiente figura muestra la comparación de rendimiento de la generación de texto entre Punica y otros sistemas, incluidos los transformadores de superficie, Deepspeed, FasterTransformer, VLLM. El punto de referencia considera diferentes configuraciones de popularidad del modelo Lora. Distints significa que cada solicitud es para un modelo Lora diferente. Idéntico significa que todas las solicitudes son para el mismo modelo Lora. Uniforme y sesgado están en el medio. Punica logra un rendimiento 12X en comparación con los sistemas de última generación.
Lea nuestro artículo para comprender más: Punica: Servicio de Lora Multi-Wenant.
Puede instalar Punica del paquete binario o construir desde la fuente.
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . Vea la demostración de arriba.
Ver examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

