punica
v1.1.0
(กระดาษ)
python examples/tui-multi-lora.pyการปรับระดับต่ำ (LORA) เป็นวิธีที่มีประสิทธิภาพในการเพิ่มความรู้ใหม่ให้กับ LLM ที่ได้รับการฝึกฝน แม้ว่า LLM ที่ได้รับการฝึกฝนจะใช้ที่เก็บ GB 100 วินาที Punica เปิดใช้งานรุ่น Lora Finetuned หลายรุ่นในราคาที่ใช้งานได้
ยังไง?
สมมติว่า W ของรูปร่าง [H1, H2] เป็นน้ำหนักของแบบจำลองที่ผ่านการฝึกฝน Lora เพิ่มเมทริกซ์ขนาดเล็กสอง A ของรูปร่าง [H1, r] และ B ของ [r, H2] การรันอินพุต x บนโมเดล finetuned จะเป็น y := x @ (W + A@B) ซึ่งเหมือนกับ y := x@W + x@A@B
เมื่อมีโมเดล n Lora จะมี A1 , B1 , A2 , B2 , ... , An , Bn ได้รับแบทช์อินพุต X := (x1,x2,...,xn) ที่แมปกับแต่ละรุ่น lora เอาต์พุตคือ Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) ด้านซ้ายมือคำนวณแบทช์อินพุตในรุ่นที่ผ่านการฝึกฝน มันค่อนข้างมีประสิทธิภาพ เวลาแฝงเกือบจะเหมือนกับเมื่อมีอินพุตเพียงครั้งเดียวขอบคุณเอฟเฟกต์การแบทช์ที่แข็งแกร่ง
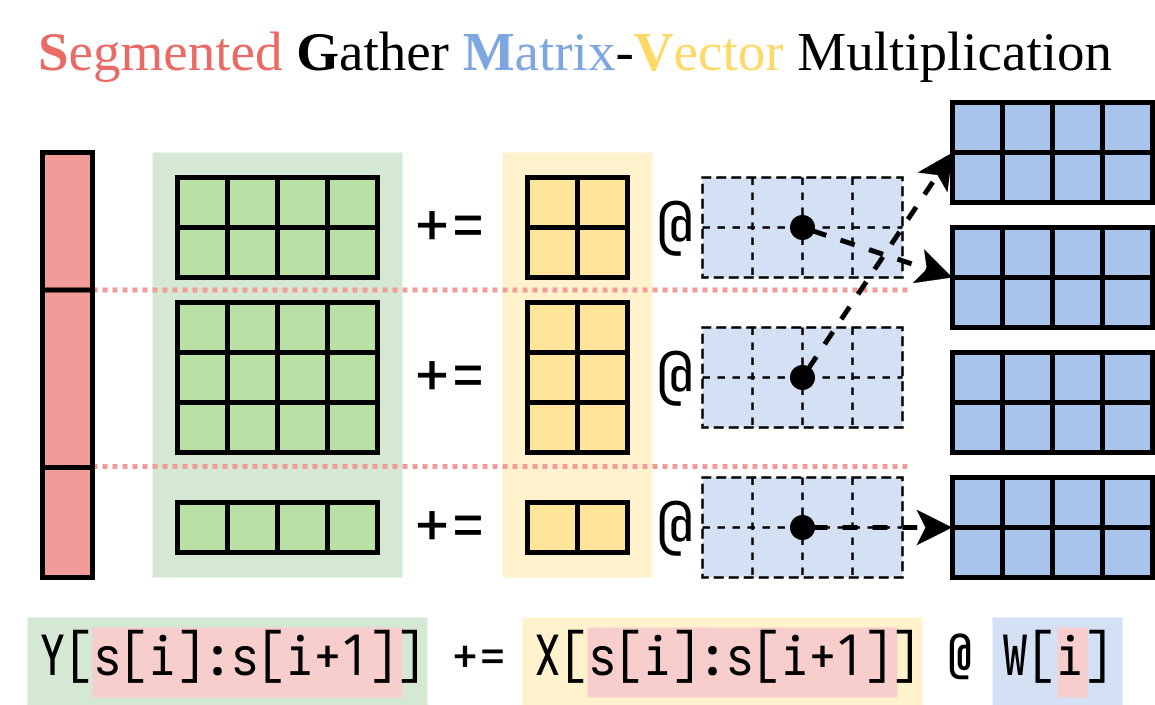
เราหาวิธีที่มีประสิทธิภาพในการคำนวณด้านขวามือ (Lora Addon) เราห่อหุ้มการดำเนินการนี้ในเคอร์เนล CUDA ที่เรียกว่าการรวมกลุ่มเมทริกซ์-เวกเตอร์การคูณ (SGMV) ดังที่แสดงด้านล่าง
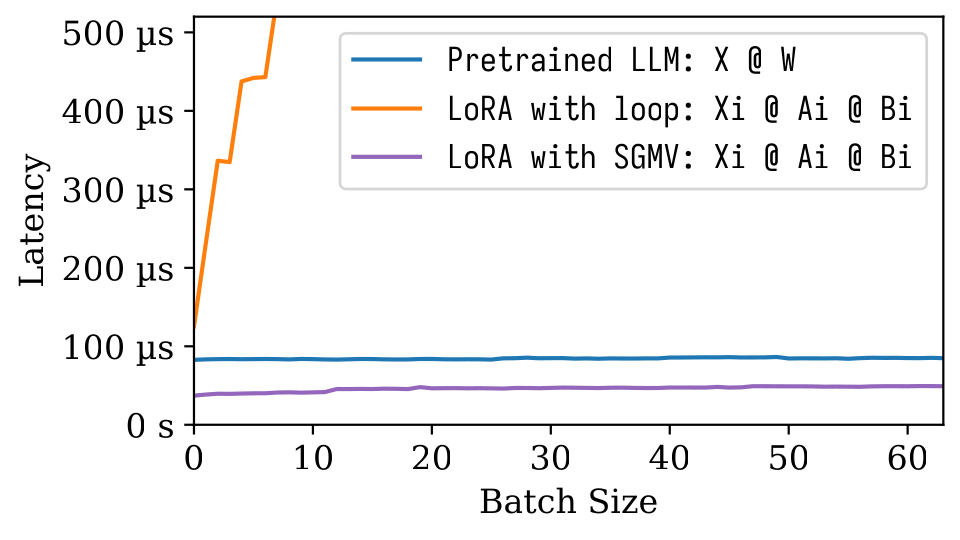
ในรูป microbenchmark ต่อไปนี้เราสามารถสังเกตผลการแบทช์ที่แข็งแกร่งของแบบจำลองที่ผ่านการฝึกอบรม การใช้งานที่ไร้เดียงสาของ LORA นั้นช้าตามที่ปรากฎในสายสีส้ม LORA ที่ดำเนินการผ่าน SGMV นั้นมีประสิทธิภาพและรักษาเอฟเฟกต์แบทช์ที่แข็งแกร่ง
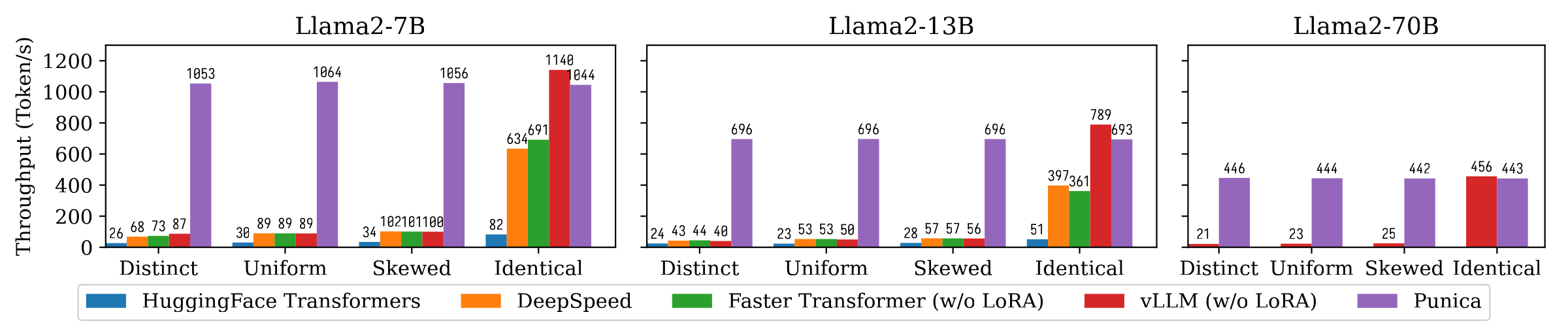
รูปต่อไปนี้แสดงการเปรียบเทียบปริมาณการสร้างข้อความระหว่าง Punica และระบบอื่น ๆ รวมถึง Transformers HuggingFace, Deepspeed, FasterTransformer, VLLM เกณฑ์มาตรฐานพิจารณาการตั้งค่าที่แตกต่างกันของความนิยมโมเดล LORA หมายถึง การ ร้องขอแต่ละครั้งสำหรับโมเดล LORA ที่แตกต่างกัน หมายความ ว่าคำขอทั้งหมดมีไว้สำหรับรุ่น LORA เดียวกัน เครื่องแบบ และ เบ้ อยู่ในระหว่าง Punica ประสบความสำเร็จในการรับส่งข้อมูล 12x เมื่อเทียบกับระบบที่ทันสมัย
อ่านกระดาษของเราเพื่อทำความเข้าใจเพิ่มเติม: Punica: ผู้เช่า Lora ที่ให้บริการ
คุณสามารถติดตั้ง punica จากแพ็คเกจไบนารีหรือสร้างจากแหล่งที่มา
8.0 8.6 8.9+PTX pip install ninja torch
pip install punica -i https://punica-ai.github.io/whl/cu121/ --extra-index-url https://pypi.org/simple
# Note: Change cu121 to your CUDA version. # Please install torch before punica
pip install ninja numpy torch
# Clone punica
git clone https://github.com/punica-ai/punica.git
cd punica
git submodule sync
git submodule update --init
# If you encouter problem while compilation, set TORCH_CUDA_ARCH_LIST to your CUDA architecture.
# export TORCH_CUDA_ARCH_LIST="8.0"
# Build and install punica
pip install -v --no-build-isolation . ดูการสาธิตด้านบน
ดู examples/finetune/
python -m benchmarks.bench_textgen_lora --system punica --batch-size 32 @misc { punica ,
title = { Punica: Multi-Tenant LoRA Serving } ,
author = { Lequn Chen and Zihao Ye and Yongji Wu and Danyang Zhuo and Luis Ceze and Arvind Krishnamurthy } ,
year = { 2023 } ,
eprint = { 2310.18547 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.DC }
}

