?濟州語語言,標準語言兩條通道語音翻譯模型創建項目
模型使用
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
?我的角色
- 數據集創建
- 翻譯模型邏輯設計
- 微調作為Kobart模型
- 在韓國韓語的Text2Text模型中, Kobart是最好,最快的模型。
- 在設計兩個邏輯的過程中,在句子前進入[Jeju]和[標準]令牌,以使模型易於理解(BLEU得分為0.5-> 0.7,最高1個標準)
- 由於缺乏RAM,僅學習了700,000個數據,但是數據集格式方法已從Float16更改為unit16來解決內存短缺(GPU內存,資源節省)
1。介紹項目
? ?隊員
- 維生素12:Lee Seo -Hyun,Lee Yerin領導者
- 維生素13:Kim Yun -Young,Kim Jae -Gyeom,Lee Hyung -Seok
?時期
?配x主題
目標
- 我們想促進對濟州外方言的理解,並為濟州文文化的保存做出貢獻。
- 我們促進與濟州公民的平穩溝通。
- 我們開發了一個兩條通道的模型,該模型將濟會方言和韓國標準語言連接起來。
- 實施語音識別和用戶界面。
2。數據收集
通過AI-HUB收集的數據
GitHub收集的數據
其他數據
- 生活省數據(Jeju初步網頁爬行)
- 好吧,Lang Harman數據(通過參考Langhaman視頻中的歌詞翻譯視頻來收集數據)
- Jeju方言的口味和時尚數據(從書中收集的數據是“ Jeju舌頭的味道和獎品”)
- 即使數據已經過去,即使它通過了,它也會從“即使已經消失”中收集數據)
- 2018 Jeju語言口頭材料收集(收集供評估)
3。模型學習
3-1。相關模型
我以某種方式學習了學習預學模型和微調。
用於開發翻譯模型的預學習模型:
- 學習模型選擇標準
- 它是翻譯的正確模型嗎?
- 它是在韓語中學到的嗎?
- 模型容量是否如此之大,學習速度很快?
已被考慮但未選擇的模型:
3-2。學習方法
學習方法
- 來源 - >目標格式學習
- 在輸入句子之前,添加[jeju]或[標準]令牌以指定翻譯和學習的方向
- 使用數據集軟件包的數據集,將其轉換為語言模型學習的優化表單
主要參數設置
- max_length:64
- batch_size:32
- Transing_rate:首先,從2E-5開始,學習進展逐漸減少
- 時代:3
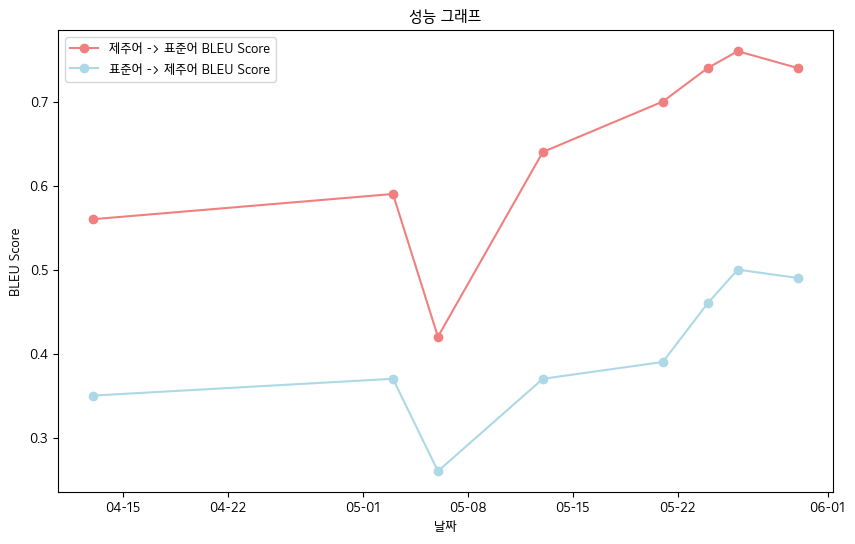
? 4。主要成就
- 最終BLEU分數-Jeju語言口頭數據簿數據標準
- 濟州語語言 - >標準語言:0.76
- 標準語言 - >智豪語言:0.5
- BLEU得分錶現表
| 日期 | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| 濟州語語言 - >標準語言bleu得分 | 0.56 | 0.59 | 0.42 | 0.64 | 0.70 | 0.74 | 0.76 | 0.74 |
| 標準語言 - > jeju bleu得分 | 0.35 | 0.37 | 0.26 | 0.37 | 0.39 | 0.46 | 0.50 | 0.49 |
接口實現
語音識別功能
- stt
- 從擁抱臉上收到耳語模型,然後進行微調
- 濟州語的語言轉換為文字並轉換為文本
- TTS
- 從擁抱臉部接收GLOS TT,Hifigan模型,然後進行微調
- 我試圖在濟州島表達聲音,但失敗了...
- 表達而不是標準語言語音(使用GTTS)
? 5。未來計劃
- 通過其他數據收集和語法微調調整以確保質量數據的初步處理
- 改善語音識別模型重音的能力
- Web實施和移動應用程序開發計劃
? 6。參考
- 數據源
- 韓國方言點火數據(由AI-HUB提供):https://www.aihub.or.kr/aihubdata/data/data/view.do?curmenu=115&topmenu
- 中間和舊韓國方言數據(AI-HUB):https://www.aihub.or.kr/aihubdata/data/data/view.do?curmenu=115&topmenu
- kakao jit jeju舌數據(請參閱kakaobrane github):https://github.com/kakaobrain/jejuo
- 生活方面的數據(請參閱Jeju語言初步):https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- 模型源
- Kobart擁抱臉:https://huggingface.co/gogamza/kobart-base-v2
- 耳語擁抱臉:https://huggingface.co/openai/whisper-large-v2
- Kobart Github:https://github.com/skt-ai/kobart


