? Jeju Sprache, Standardsprache Zwei -Way -Sprachübersetzungsmodell Erstellungsprojekt
Modellgebrauch
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
? Meine Rolle
- Datensatzerstellung
- Jeju-Standard-Datensatzsammlung und Vorbereitung für den neuen Datensatz (Datensatz)
- Datenerfassung wie AI-Hub, Github usw.
- Übersetzungsmodell -Logikdesign
- Feinabstimmung als Kbart -Modell
- Unter den Text2Text -Modellen in Koreanisch in Koreanisch ist Kartart das beste und schnellste Modell.
- Beim Entwerfen zweier Logiks , die [Jeju] und [Standard] Token vor dem Satz eingeben, um das Modell leicht zu verstehen (Bleu -Score 0,5-> 0,7, bis zu 1 Standard)
- Aufgrund des Mangels an RAM wurden nur 700.000 Daten gelernt , aber die Datensatzformatmethode wurde von Float16 auf Unit16 geändert, um Speichermangel zu lösen (GPU -Speicher, Ressourcensparung).
1. Einführung des Projekts
??? Teammitglied
- Vitamin 12: Leader, Lee Seo -Hyun, Lee Yerin
- Vitamin 13: Kim Yun -Young, Kim Jae -gyeom, Lee Hyung -seok
? Zeitraum
? ️ Thema
Ziel
- Wir möchten das Verständnis von Jeju -Dialekten fördern und zur Erhaltung der Jeju -Kultur beitragen.
- Wir fördern eine reibungslose Kommunikation mit den Bürgern in Jeju.
- Wir entwickeln ein Zwei -Wege -Übersetzungsmodell, das den Jeju -Dialekt und die koreanische Standardsprache verbindet.
- Implementierung der Spracherkennung und Benutzeroberfläche.
2. Datenerfassung
3. Modelllernen
3-1. Modellbezogen
Ich habe gelernt, das Vorliesemodell und die Feinabstimmung einzubringen .
Vor -Learning -Modell zur Entwicklung von Übersetzungsmodellen:
Vor -Learning -Modellauswahlkriterien
- Ist es das richtige Modell für die Übersetzung?
- Ist es auf Koreanisch gelernt?
- Ist die Modellkapazität so groß und die Lerngeschwindigkeit ist schnell?
Modelle, die berücksichtigt wurden, aber nicht ausgewählt wurden:
- T5 (Es gibt ein Problem mit einer zu langen Lernzeit)
- Jebert (Leistung war nicht zufriedenstellend)
3-2. Lernmethode
? 4. Haupter Leistungen
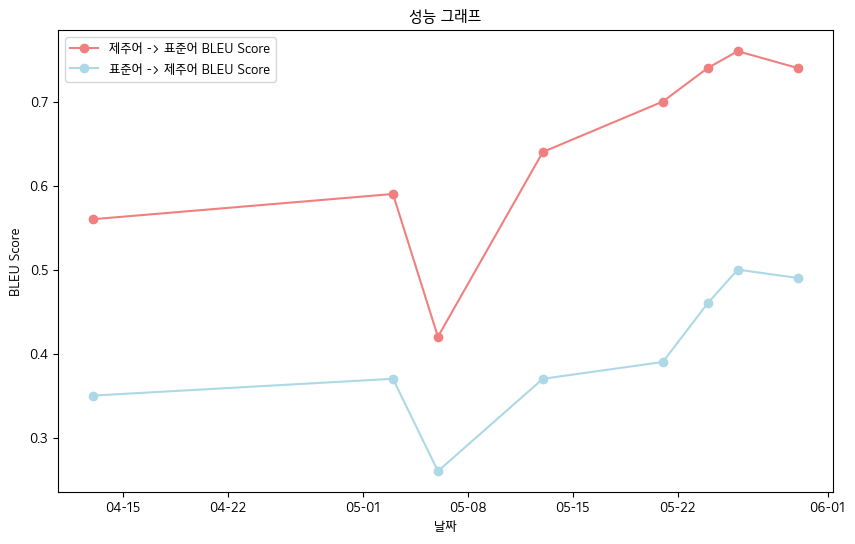
- Endgültige BLEU -Score -jeju Sprache Orale Datenbuchdatenstandards
- Jeju Sprache-> Standardsprache: 0,76
- Standardsprache-> Jeju Sprache: 0,5
- Bleu -Score -Leistungstabelle
| Datum | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| Jeju Sprache-> Standard Sprache Bleu Score | 0,56 | 0,59 | 0,42 | 0,64 | 0,70 | 0,74 | 0,76 | 0,74 |
| Standardsprache-> Jeju Bleu Score | 0,35 | 0,37 | 0,26 | 0,37 | 0,39 | 0,46 | 0,50 | 0,49 |
- Insgesamt haben wir den Bleu -Score verzeichnet .
? 5. Zukunftspläne
- Vorverarbeitung durch zusätzliche Datenerfassung und grammatische Mikroanpassung zur Sicherung von Qualitätsdaten
- Verbesserung der Fähigkeit, den Akzent des Spracherkennungsmodells zu erkennen
- Web -Implementierung und Entwicklungsplan für mobile Apps
? 6. Referenz
- Datenquelle
- Koreanische Dialekt-Zünddaten (bereitgestellt von ai-hub): https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- Mittlere und ältere koreanische Dialektdaten (AI-Hub): https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- Kakao Jit Jeju Zungendaten (siehe Kakaobrane Github): https://github.com/kakaobrain/jejuo
- Living Living Side -Daten (siehe JEJU -Sprache vorläufig): https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- Modellquelle
- Karting-Umarmung Gesicht: https://huggingface.co/gogamza/kobart-base-v2
- Flüsterns umarmtes Gesicht: https://huggingface.co/openai/whisper-large-v2
- Kbart Github: https://github.com/skt-ai/kobart


