?済州言語、標準言語2ウェイ音声翻訳モデル作成プロジェクト
モデルの使用
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
?私の役割
- データセット作成
- 経済標準のデータセットコレクションと新しいデータセットの準備(データセット)
- 翻訳モデルロジック設計
- Kobartモデルとしての微調整
- 韓国語の韓国語のText2Textモデルの中で、 Kobartは最高で最速のモデルです。
- 2つのウェイロジックを設計する過程で、[jeju]と[標準]トークンの文の前にトークンを入力して、モデルを理解しやすくします(Bleuスコア0.5-> 0.7、最大1標準)
- RAMが不足しているため、700,000のデータしか学習されませんでしたが、メモリ不足(GPUメモリ、リソースの保存)を解決するために、データセット形式の方法がFloat16からUnit16に変更されました。
1。プロジェクトの導入
????チームメンバー
- ビタミン12:リーダー、リー・ソ - ヒョン、リー・イェリン
- ビタミン13:キム・ユン-Young、Kim Jae -Gyeom、Lee Hyung -Seok
?期間
? §テーマ
- 済州方言と標準的な言語の双方向翻訳モデルを作成します
ターゲット
- 済州方言の理解を促進し、済州文化の保存に貢献したいと思います。
- 済州の市民とのスムーズなコミュニケーションを促進します。
- 済州方言と韓国の標準言語をつなぐ2つの方向の翻訳モデルを開発します。
- 音声認識とユーザーインターフェイスの実装。
2。データ収集
AIハブによって収集されたデータ
Githubによって収集されたデータ
その他のデータ
- 生きている州のデータ(済州の予備的なWebページクローリング)
- さて、Lang Harman Data(Langhamanビデオの中で歌詞翻訳ビデオを参照することによるYouTuberデータコレクション)
- 済州方言は、味とスタイリッシュなデータ(済州の舌の味と賞品」から収集されたデータ)のデータ)
- データが消えたとしても、たとえ通過しても、「それがなくなっても」という本からデータを収集します)
- 2018 jeju言語口頭材料コレクション(評価のために収集)
3。モデル学習
3-1。モデル関連
3-2。学習方法
学習方法論
- ソース - >ターゲット形式の学習
- 文を入力する前に、[jeju]または[標準]トークンを追加して、翻訳と学習の方向を一緒に指定します
- データセットパッケージのデータセットを使用して、言語モデル学習のために最適化されたフォームに変換します
主なパラメーター設定
- max_length:64
- batch_size:32
- Transing_rate:最初は2E-5から始まり、学習が徐々に減少しました
- エポック:3
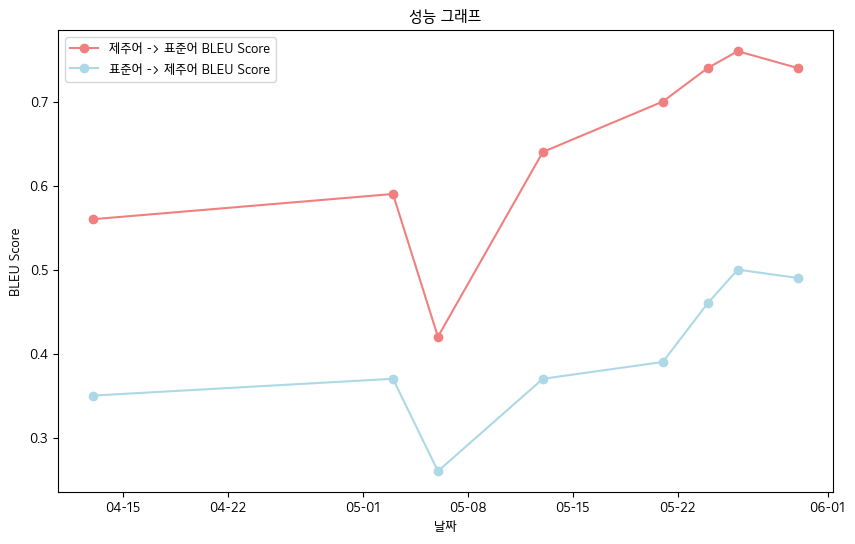
? 4。主な成果
- 最終的なブルースコア-Jeju言語口頭データ帳データ基準
- 済州言語 - >標準言語:0.76
- 標準言語 - >済州言語:0.5
- ブルースコアパフォーマンステーブル
| 日付 | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| 済州言語 - >標準言語BLEUスコア | 0.56 | 0.59 | 0.42 | 0.64 | 0.70 | 0.74 | 0.76 | 0.74 |
| 標準言語 - > jeju bleuスコア | 0.35 | 0.37 | 0.26 | 0.37 | 0.39 | 0.46 | 0.50 | 0.49 |
インターフェイスの実装
音声認識関数
- stt
- 顔を抱きしめることからささやきモデルを受け取り、微調整を進めます
- 済州言語テキストへの変換とテキストへの変換
- TTS
- グロスTTS、Hugging FaceからHifiganモデルを受け取り、微調整を進めます
- 済州で声を表現しようとしましたが、失敗しました...
- 標準言語音声の代わりに式(GTTを使用)
? 5。将来の計画
- 追加のデータ収集と文法マイクロ調整による予備処理品質データを保護する
- 音声認識モデルのアクセントを認識する能力の改善
- Web実装およびモバイルアプリ開発計画
? 6。リファレンス
- データソース
- 韓国方言イグニッションデータ(AI-Hubが提供):https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- 中および古い韓国方言データ(AI-HUB):https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- kakao jit jeju tongue Data(Kakaobrane githubを参照):https://github.com/kakaobrain/jejuo
- リビングリビングサイドデータ(jeju言語予備的予備を参照):https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- モデルソース
- Kobart Hugging Face:https://huggingface.co/gogamza/kobart-base-v2
- ささやきの顔:https://huggingface.co/openai/whisper-large-v2
- Kobart Github:https://github.com/skt-ai/kobart


