?济州语语言,标准语言两条通道语音翻译模型创建项目
模型使用
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
?我的角色
- 数据集创建
- 翻译模型逻辑设计
- 微调作为Kobart模型
- 在韩国韩语的Text2Text模型中, Kobart是最好,最快的模型。
- 在设计两个逻辑的过程中,在句子前进入[Jeju]和[标准]令牌,以使模型易于理解(BLEU得分为0.5-> 0.7,最高1个标准)
- 由于缺乏RAM,仅学习了700,000个数据,但是数据集格式方法已从Float16更改为unit16来解决内存短缺(GPU内存,资源节省)
1。介绍项目
??队员
- 维生素12:Lee Seo -Hyun,Lee Yerin领导者
- 维生素13:Kim Yun -Young,Kim Jae -Gyeom,Lee Hyung -Seok
?时期
?配x主题
目标
- 我们想促进对济州外方言的理解,并为济州文文化的保存做出贡献。
- 我们促进与济州公民的平稳沟通。
- 我们开发了一个两条通道的模型,该模型将济会方言和韩国标准语言连接起来。
- 实施语音识别和用户界面。
2。数据收集
通过AI-HUB收集的数据
GitHub收集的数据
其他数据
- 生活省数据(Jeju初步网页爬行)
- 好吧,Lang Harman数据(通过参考Langhaman视频中的歌词翻译视频来收集数据)
- Jeju方言的口味和时尚数据(从书中收集的数据是“ Jeju舌头的味道和奖品”)
- 即使数据已经过去,即使它通过了,它也会从“即使已经消失”中收集数据)
- 2018 Jeju语言口头材料收集(收集供评估)
3。模型学习
3-1。相关模型
我以某种方式学习了学习预学模型和微调。
用于开发翻译模型的预学习模型:
- 学习模型选择标准
- 它是翻译的正确模型吗?
- 它是在韩语中学到的吗?
- 模型容量是否如此之大,学习速度很快?
已被考虑但未选择的模型:
3-2。学习方法
学习方法
- 来源 - >目标格式学习
- 在输入句子之前,添加[jeju]或[标准]令牌以指定翻译和学习的方向
- 使用数据集软件包的数据集,将其转换为语言模型学习的优化表单
主要参数设置
- max_length:64
- batch_size:32
- Transing_rate:首先,从2E-5开始,学习进展逐渐减少
- 时代:3
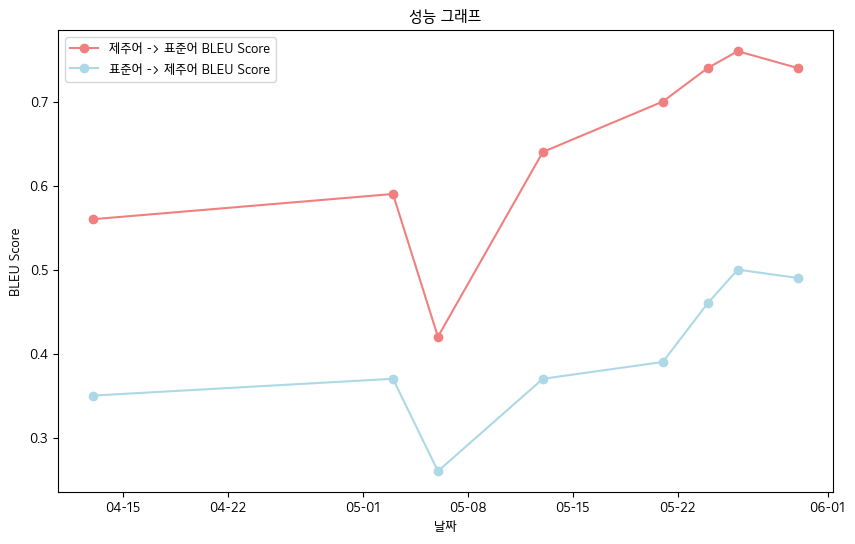
? 4。主要成就
- 最终BLEU分数-Jeju语言口头数据簿数据标准
- 济州语语言 - >标准语言:0.76
- 标准语言 - >智豪语言:0.5
- BLEU得分表现表
| 日期 | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| 济州语语言 - >标准语言bleu得分 | 0.56 | 0.59 | 0.42 | 0.64 | 0.70 | 0.74 | 0.76 | 0.74 |
| 标准语言 - > jeju bleu得分 | 0.35 | 0.37 | 0.26 | 0.37 | 0.39 | 0.46 | 0.50 | 0.49 |
接口实现
语音识别功能
- stt
- 从拥抱脸上收到耳语模型,然后进行微调
- 济州语的语言转换为文字并转换为文本
- TTS
- 从拥抱脸部接收GLOS TT,Hifigan模型,然后进行微调
- 我试图在济州岛表达声音,但失败了...
- 表达而不是标准语言语音(使用GTTS)
? 5。未来计划
- 通过其他数据收集和语法微调调整以确保质量数据的初步处理
- 改善语音识别模型重音的能力
- Web实施和移动应用程序开发计划
? 6。参考
- 数据源
- 韩国方言点火数据(由AI-HUB提供):https://www.aihub.or.kr/aihubdata/data/data/view.do?curmenu=115&topmenu
- 中间和旧韩国方言数据(AI-HUB):https://www.aihub.or.kr/aihubdata/data/data/view.do?curmenu=115&topmenu
- kakao jit jeju舌数据(请参阅kakaobrane github):https://github.com/kakaobrain/jejuo
- 生活方面的数据(请参阅Jeju语言初步):https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- 模型源
- Kobart拥抱脸:https://huggingface.co/gogamza/kobart-base-v2
- 耳语拥抱脸:https://huggingface.co/openai/whisper-large-v2
- Kobart Github:https://github.com/skt-ai/kobart


