? Lenguaje Jeju, Idioma estándar Proyecto de creación de modelos de traducción de voz de dos vías
Uso del modelo
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
? Mi papel
- Creación de conjuntos de datos
- Jeju Standard DataSet Collection and Preparation para un nuevo conjunto de datos (conjunto de datos)
- Recopilación de datos como Ai-Hub, Github, etc.
- Diseño lógico del modelo de traducción
- Tonte fino como modelo de Kobart
- Entre los modelos Text2Text en coreano en coreano, Kobart es el mejor y más rápido modelo.
- En el proceso de diseño de la lógica de dos vías , entrando [jeju] y tokens [estándar] frente a la oración para hacer que el modelo sea fácil de entender (puntaje Bleu 0.5-> 0.7, hasta 1 estándar)
- Debido a la falta de RAM, solo se aprendieron 700,000 datos , pero el método del formato del conjunto de datos se cambió de Float16 a la Unidad16 para resolver la escasez de memoria (memoria GPU, ahorro de recursos)
1. Introducción del proyecto
???? Miembro del equipo
- Vitamina 12: Líder, Lee Seo -Hyun, Lee Yerin
- Vitamina 13: Kim Yun -young, Kim Jae -Gyeom, Lee Hyung -Seok
? período
? Tema de ️
- Crear dialecto jeju y modelo de traducción bidireccional de idioma estándar
objetivo
- Nos gustaría promover la comprensión de los dialectos de Jeju y contribuir a la preservación de la cultura Jeju.
- Promovemos una comunicación sin problemas con los ciudadanos en Jeju.
- Desarrollamos un modelo de traducción de dos vías que conecta el dialecto Jeju y el lenguaje estándar coreano.
- Implementación de reconocimiento de voz e interfaz de usuario.
2. Recopilación de datos
3. Aprendizaje modelo
3-1. Relacionado con el modelo
Aprendí en una forma de traer el modelo previo al aprendizaje y el ajuste .
Modelo previo al aprendizaje utilizado para desarrollar modelos de traducción:
Criterios de selección de modelos previos al aprendizaje
- ¿Es el modelo adecuado para la traducción?
- ¿Se aprende en coreano?
- ¿Es la capacidad del modelo tan grande y la velocidad de aprendizaje es rápida?
Modelos que han sido considerados pero no seleccionados:
- T5 (hay un problema con el tiempo de aprendizaje demasiado largo)
- Jebert (el rendimiento no fue satisfactorio)
3-2. Método de aprendizaje
? 4. Logros principales
- Normas de datos de libros de datos orales de Lengua Oral de Lenguaje de JeJu
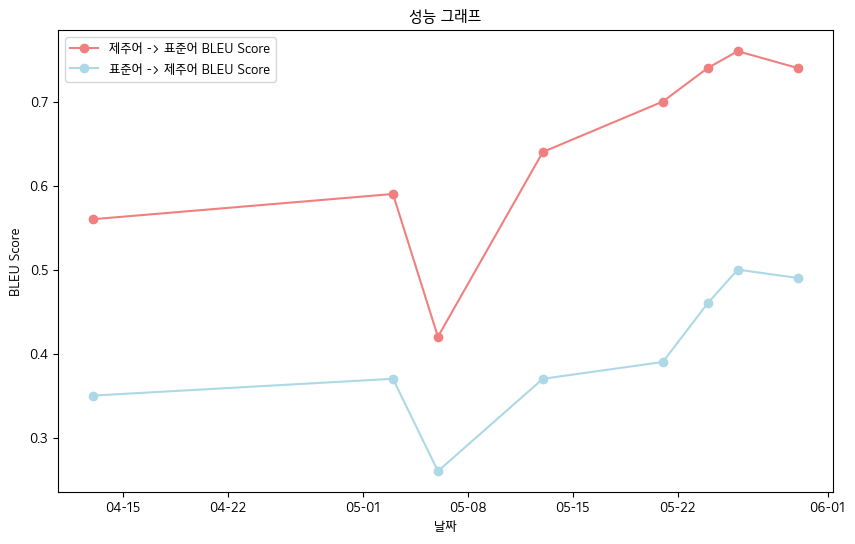
- Jeju Language-> Idioma estándar: 0.76
- Lenguaje estándar-> Jeju Lenguaje: 0.5
- Tabla de rendimiento de puntuación de bleu
| fecha | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| Jeju Language-> Puntuación de lenguaje estándar Bleu | 0.56 | 0.59 | 0.42 | 0.64 | 0.70 | 0.74 | 0.76 | 0.74 |
| Lenguaje estándar-> Jeju Bleu Puntuación | 0.35 | 0.37 | 0.26 | 0.37 | 0.39 | 0.46 | 0.50 | 0.49 |
- En general, registramos la puntuación BLEU .
? 5. Planes futuros
- Procesamiento preliminar a través de la recopilación de datos adicional y el microjustación gramaticular para asegurar datos de calidad
- Mejora de la capacidad de reconocer el acento del modelo de reconocimiento de voz
- Implementación web y plan de desarrollo de aplicaciones móviles
? 6. Referencia
- Fuente de datos
- Datos de encendido del dialecto coreano (proporcionados por ai-hub): https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- Datos del dialecto coreano medio y anterior (Ai-Hub): https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- Datos de lengua Kakao Jit Jeju (ver Kakaobrane Github): https://github.com/kakaobrain/JeJUO
- Datos del lado vivo (ver Jeju Language Preliminar): https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- Fuente de modelos
- Kobart abrazando la cara: https://huggingface.co/gogamza/kobart-base-v2
- Whisper Hugging Face: https://huggingface.co/openai/whisper-large-v2
- Kobart Github: https://github.com/skt-ai/kobart


