? Linguagem Jeju, Linguagem Padrão de Tradução de Voz de Voz Padrão Projeto de Criação de Modelo
Uso do modelo
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
? Meu papel
- Criação do conjunto de dados
- Coleção e preparação do conjunto de dados do Jeju-Standard para o novo conjunto de dados (conjunto de dados)
- Coleta de dados como ai-hub, github, etc.
- Design de lógica do modelo de tradução
- Ajuste fina como um modelo Kobart
- Entre os modelos Text2Text em coreano em coreano, Kobart é o melhor e mais rápido modelo.
- No processo de projetar lógica de duas via , entrando em [Jeju] e [Standard] Tokens em frente à frase para facilitar o entendimento do modelo (pontuação Bleu de 0,5-> 0,7, até 1 padrão)
- Devido à falta de RAM, apenas 700.000 dados foram aprendidos , mas o método do formato do conjunto de dados foi alterado de Float16 para Unit16 para resolver escassez de memória (memória da GPU, economia de recursos)
1. Introdução do projeto
??? Membro da equipe
- Vitamina 12: Líder, Lee Seo -Hyun, Lee Yerin
- Vitamina 13: Kim Yun -young, Kim Jae -gyeom, Lee Hyung -seok
? período
? ️ tema
- Crie o dialeto jeju e o modelo de tradução bidirecional de linguagem padrão
alvo
- Gostaríamos de promover o entendimento dos dialetos de Jeju e contribuir para a preservação da cultura Jeju.
- Promovemos uma comunicação suave com os cidadãos em Jeju.
- Desenvolvemos um modelo de tradução de dois caminhos que conecta o dialeto jeju e o idioma padrão coreano.
- Implementando reconhecimento de voz e interface do usuário.
2. Coleta de dados
3. Aprendizagem de modelo
3-1. Modelo relacionado
Aprendi de maneira a trazer o modelo de pré-aprendizagem e o ajuste fino .
Modelo de pré -aprendizagem usado para desenvolver modelos de tradução:
Critérios de seleção de modelo de pré -aprendizagem
- É o modelo certo para tradução?
- É aprendido em coreano?
- A capacidade do modelo é tão grande e a velocidade de aprendizado é rápida?
Modelos que foram considerados, mas não selecionados:
- T5 (há um problema com tempo de aprendizado muito longo)
- Jebert (o desempenho não foi satisfatório)
3-2. Método de aprendizado
? 4. Principais realizações
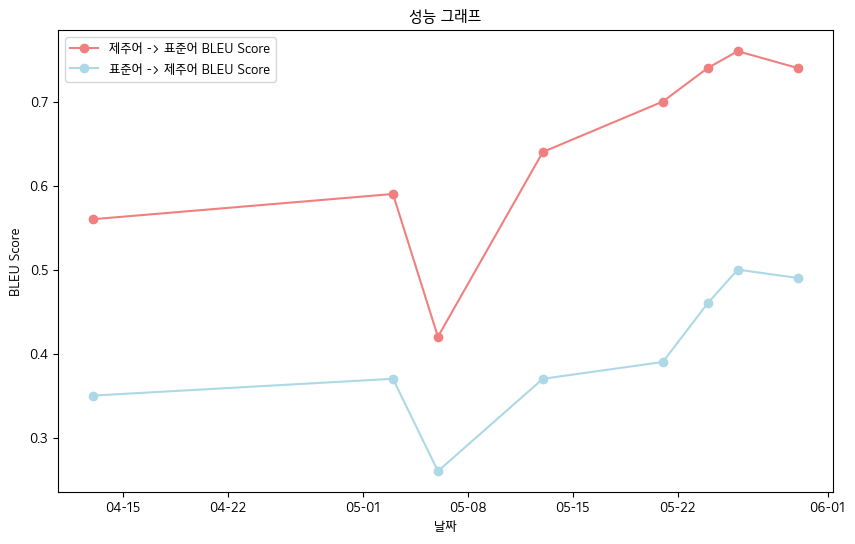
- Final Bleu Score -Jeju idioma Oral Data Book Standards
- Idioma jeju-> idioma padrão: 0,76
- Linguagem padrão-> idioma jeju: 0.5
- Tabela de desempenho de pontuação bleu
| data | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| Idioma de jeju-> pontuação de idioma padrão bleu | 0,56 | 0,59 | 0,42 | 0,64 | 0,70 | 0,74 | 0,76 | 0,74 |
| Linguagem padrão-> pontuação jeju bleu | 0,35 | 0,37 | 0,26 | 0,37 | 0,39 | 0,46 | 0,50 | 0,49 |
- No geral, registramos a pontuação Bleu .
? 5. Planos futuros
- Processamento preliminar por meio de coleta de dados adicionais e micro -ajuste gramático para proteger dados de qualidade
- Melhoria da capacidade de reconhecer o sotaque do modelo de reconhecimento de voz
- Implementação da Web e plano de desenvolvimento de aplicativos móveis
? 6. Referência
- Fonte de dados
- Dados de ignição do dialeto coreano (fornecidos por AI-hub): https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- Dados de dialeto coreano médio e mais antigo (AI-hub): https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- Kakao Jit Jeju Tongue Data (ver Kakaobrane Github): https://github.com/kakaobrain/jejuo
- Dados vivos do lado vivo (ver Jeju Language Preliminar): https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- Fonte de modelo
- KOBART Abraçando o rosto: https://huggingface.co/gogamza/kobart-base-v2
- Whisper Hugging Face: https://huggingface.co/openai/whisper-large-v2
- Kobart Github: https://github.com/skt-ai/kobart


