? Langue Jeju, Langue standard à deux projets de traduction vocale Projet de création
Utilisation du modèle
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
? Mon rôle
- Création d'ensemble de données
- Collection et préparation de l'ensemble de données JEJU-Standard pour un nouvel ensemble de données (ensemble de données)
- Collecte de données comme Ai-Hub, GitHub, etc.
- Conception logique du modèle de traduction
- Réglage fin en tant que modèle Kobart
- Parmi les modèles text2text en coréen en coréen, Kobart est le modèle le meilleur et le plus rapide.
- Dans le processus de conception de la logique à deux voies , entrant [Jeju] et [Standard] jetons devant la phrase pour rendre le modèle facile à comprendre (score BLEU 0,5 à> 0,7, jusqu'à 1 standard)
- En raison du manque de RAM, seulement 700 000 données ont été apprises , mais la méthode du format de jeu de données a été changée de Float16 à Unit16 pour résoudre les pénuries de mémoire (mémoire GPU, enregistrement des ressources)
1. Introduction du projet
??? Membre de l'équipe
- Vitamine 12: Leader, Lee Seo -Hyun, Lee Yerin
- Vitamine 13: Kim Yun -young, Kim Jae -Gyeom, Lee Hyung -Seok
? période
? ️ thème
- Créer un dialecte Jeju et un modèle de traduction bidirectionnelle en langage standard
cible
- Nous aimerions promouvoir la compréhension des dialectes Jeju et contribuer à la préservation de la culture Jeju.
- Nous promouvons une communication fluide avec les citoyens de Jeju.
- Nous développons un modèle de traduction à deux voies qui relie le dialecte Jeju et la langue standard coréenne.
- Implémentation de la reconnaissance vocale et de l'interface utilisateur.
2. Collecte de données
3. Apprentissage du modèle
3-1-1. Lié au modèle
J'ai appris de manière à apporter le modèle de pré-apprentissage et le réglage fin .
Modèle de pré-apprentissage utilisé pour développer des modèles de traduction:
Critères de sélection du modèle de pré-apprentissage
- Est-ce le bon modèle de traduction?
- Est-il appris en coréen?
- La capacité du modèle est-elle si grande et la vitesse d'apprentissage est rapide?
Modèles qui ont été considérés mais non sélectionnés:
- T5 (il y a un problème avec un temps d'apprentissage trop long)
- Jebert (la performance n'était pas satisfaisante)
3-2. Méthode d'apprentissage
? 4. Réalisations principales
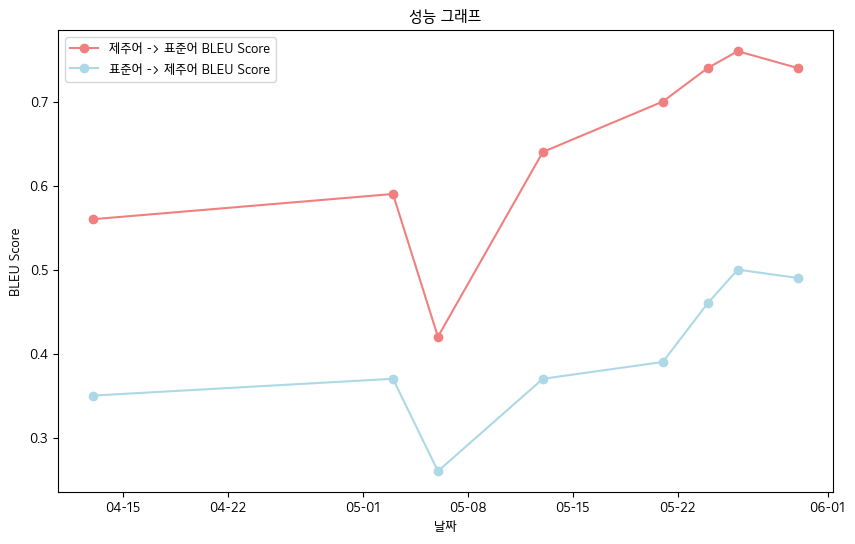
- Score BLEU final -JEJU Langue Oral Data Book Normes de données
- Langue Jeju-> Langue standard: 0,76
- Langue standard-> Langue Jeju: 0,5
- Table de performance BLEU SCORE
| date | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| Langue Jeju-> Langue standard Bleu Score | 0,56 | 0,59 | 0,42 | 0,64 | 0,70 | 0,74 | 0,76 | 0,74 |
| Langue standard-> Jeju bleu score | 0,35 | 0,37 | 0,26 | 0,37 | 0,39 | 0,46 | 0,50 | 0,49 |
- Dans l'ensemble, nous avons enregistré le score BLEU .
? 5. Plans futurs
- Traitement préliminaire grâce à une collecte de données supplémentaires et à un micro-ajustement grammatique pour sécuriser les données de qualité
- Amélioration de la capacité à reconnaître l'accent du modèle de reconnaissance vocale
- Plan de mise en œuvre Web et de développement d'applications mobiles
? 6. Référence
- Source de données
- Données coréennes d'allumage du dialecte (fournies par Ai-Hub): https://www.aihub.or.kr/aihubdata/data/view.do?curMenu=115&topmenu
- Données de dialecte coréen moyen et ancienne (Ai-Hub): https://www.aihub.or.kr/aihubdata/data/view.do?curMenu=115&topmenu
- Kakao Jit Jeju Données de la langue (voir Kakaobrane Github): https://github.com/kakaobrain/jejuo
- Données de vie vivantes (voir la langue Jeju préliminaire): https://www.jeju.go.kr/culture/dialect/lifeDialect.htm
- Source du modèle
- Kobart Hugging Face: https://huggingface.co/gogamza/kobart-base-v2
- Face étreinte de chuchotement: https://huggingface.co/openai/whisper-large-v2
- Kobart Github: https://github.com/skt-ai/kobart


