- ภาษา jeju, ภาษามาตรฐานสอง -โครงการสร้างรูปแบบการแปลด้วยเสียงแบบสองทาง
การใช้แบบจำลอง
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
- บทบาทของฉัน
- การสร้างชุดข้อมูล
- ชุดข้อมูลชุดข้อมูล Jeju-Standard และการเตรียมการสำหรับชุดข้อมูลใหม่ (ชุดข้อมูล)
- การรวบรวมข้อมูลเช่น AI-Hub, GitHub ฯลฯ
- การออกแบบตรรกะแบบจำลองการแปล
- ปรับจูนเป็นรุ่น Kobart
- ในบรรดาโมเดล Text2Text ในเกาหลีในเกาหลี Kobart เป็นรุ่นที่ดีที่สุดและเร็วที่สุด
- ในกระบวนการออกแบบตรรกะสองทาง เข้าสู่ [jeju] และ [มาตรฐาน] โทเค็นหน้าประโยคเพื่อให้แบบจำลองเข้าใจง่าย (คะแนน Bleu 0.5-> 0.7, สูงสุด 1 มาตรฐาน)
- เนื่องจากการขาด RAM มีการเรียนรู้ข้อมูลเพียง 700,000 ข้อมูล แต่วิธีการจัดรูปแบบชุดข้อมูลเปลี่ยนจาก Float16 เป็น Unit16 เพื่อแก้ปัญหาการขาดแคลนหน่วยความจำ (หน่วยความจำ GPU การบันทึกทรัพยากร)
1. การแนะนำโครงการ
?? สมาชิกในทีม
- วิตามิน 12: ผู้นำ, Lee Seo -Hyun, Lee Yerin
- วิตามิน 13: Kim Yun -young, Kim Jae -Gyeom, Lee Hyung -Seok
- ระยะเวลา
- ️ ธีม
- สร้างรูปแบบการแปลแบบสองทิศทางของภาษาและภาษามาตรฐาน
เป้า
- เราต้องการส่งเสริมความเข้าใจของภาษาเจจูและมีส่วนร่วมในการอนุรักษ์วัฒนธรรม Jeju
- เราส่งเสริมการสื่อสารที่ราบรื่นกับประชาชนใน Jeju
- เราพัฒนารูปแบบการแปลสองทางที่เชื่อมต่อภาษา Jeju และภาษามาตรฐานเกาหลี
- การใช้การจดจำเสียงและส่วนต่อประสานผู้ใช้
2. การรวบรวมข้อมูล
3. การเรียนรู้แบบจำลอง
3-1. แบบจำลองที่เกี่ยวข้อง
ฉันเรียนรู้ วิธีที่จะนำรูปแบบการเรียนรู้ล่วงหน้าและการปรับแต่ง
แบบจำลองการเรียนรู้ก่อนที่ใช้ในการพัฒนารูปแบบการแปล:
เกณฑ์การเลือกแบบจำลองการเรียนรู้ล่วงหน้า
- มันเป็นแบบจำลองที่เหมาะสมสำหรับการแปลหรือไม่?
- มันเรียนรู้เป็นภาษาเกาหลีหรือไม่?
- ความสามารถของแบบจำลองนั้นใหญ่มากและความเร็วการเรียนรู้เร็วหรือไม่?
แบบจำลองที่ได้รับการพิจารณา แต่ไม่ได้เลือก:
- T5 (มีปัญหากับเวลาเรียนรู้ที่ยาวเกินไป)
- เจเบิร์ต (การแสดงไม่เป็นที่น่าพอใจ)
3-2. วิธีการเรียนรู้
- 4. ความสำเร็จหลัก
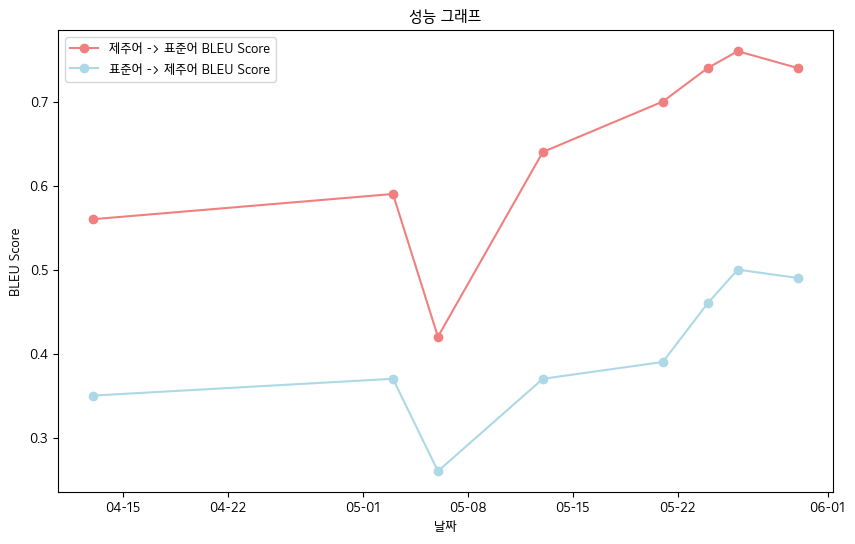
- คะแนน bleu สุดท้าย -jeju ภาษาข้อมูลข้อมูลหนังสือข้อมูลมาตรฐานข้อมูลมาตรฐาน
- ภาษา jeju-> ภาษามาตรฐาน: 0.76
- ภาษามาตรฐาน-> ภาษาเชจู: 0.5
- ตารางประสิทธิภาพของ Bleu คะแนน
| วันที่ | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| jeju language-> คะแนนภาษามาตรฐาน bleu | 0.56 | 0.59 | 0.42 | 0.64 | 0.70 | 0.74 | 0.76 | 0.74 |
| ภาษามาตรฐาน-> คะแนน Jeju Bleu | 0.35 | 0.37 | 0.26 | 0.37 | 0.39 | 0.46 | 0.50 | 0.49 |
- โดยรวมแล้ว เราบันทึกคะแนน Bleu
การใช้งานส่วนต่อประสาน
ฟังก์ชั่นการจดจำเสียง
- STT
- รับรุ่นกระซิบจากการกอดใบหน้าและดำเนินการปรับแต่งอย่างละเอียด
- การแปลงภาษา jeju เป็นข้อความและแปลงเป็นข้อความ
- TTS
- รับแบบจำลอง glos tts, hifigan จากการกอดใบหน้าและดำเนินการปรับแต่งอย่างละเอียด
- ฉันพยายามแสดงเสียงใน Jeju แต่ล้มเหลว ...
- การแสดงออกแทนเสียงภาษามาตรฐาน (โดยใช้ GTTs)
- 5. แผนการในอนาคต
- การประมวลผลเบื้องต้นผ่านการรวบรวมข้อมูลเพิ่มเติม
- การปรับปรุงความสามารถในการจดจำสำเนียงของรูปแบบการจดจำเสียง
- การใช้งานเว็บและแผนพัฒนาแอพมือถือ
- 6. การอ้างอิง
- แหล่งข้อมูล
- ข้อมูลการจุดระเบิดภาษาเกาหลี (จัดทำโดย AI-HUB): https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- ข้อมูลภาษาเกาหลีระดับกลางและเก่ากว่า (ai-hub): https://www.aihub.or.kr/aihubdata/data/view.do?curmenu=115&topmenu
- ข้อมูลลิ้น kakao jeju (ดู kakaobrane github): https://github.com/kakaobrain/jejuo
- ข้อมูลด้านการใช้ชีวิต (ดูภาษา jeju เบื้องต้น): https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- แหล่งที่มาของแบบจำลอง
- Kobart Hugging Face: https://huggingface.co/gogamza/kobart-base-v2
- Whisper Hugging Face: https://huggingface.co/openai/whisper-large-v2
- Kobart GitHub: https://github.com/skt-ai/kobart


