? Jeju language, standard language two -way voice translation model creation project
Model use
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
? My role
- Dataset creation
- Jeju-Standard Dataset Collection and Preparation for New Dataset (Dataset)
- Data collection such as AI-Hub, Github, etc.
- Translation model logic design
- Fine tuning as a KOBART model
- Among the text2Text models in Korean in Korean, Kobart is the best and fastest model.
- In the process of designing two -way logic , entering [Jeju] and [Standard] tokens in front of the sentence to make the model easy to understand (BLEU Score 0.5-> 0.7, up to 1 standard)
- Due to the lack of RAM, only 700,000 data were learned , but the dataset format method was changed from Float16 to Unit16 to solve memory shortages (GPU memory, resource saving)
1. Introduction of project
??? Team member
- Vitamin 12: Leader, Lee Seo -hyun, Lee Yerin
- Vitamin 13: Kim Yun -young, Kim Jae -gyeom, Lee Hyung -seok
? period
? ️ theme
- Create Jeju dialect and standard language bidirectional translation model
target
- We would like to promote the understanding of Jeju dialects and contribute to the preservation of Jeju culture.
- We promote smooth communication with citizens in Jeju.
- We develop a two -way translation model that connects the Jeju dialect and the Korean standard language.
- Implementing voice recognition and user interface.
2. Data collection
Data collected by AI-HUB
- Korean dialect ignition data
- Korean and older Korean dialect data
Data collected by Github
- Kakao JIT Jeju Tongue Data
Other data
- Living Province Data (Jeju Preliminary web page crawling)
- Well, Lang Harman Data (YouTuber Collection of Data by referring to the lyrics translation video among the Langhaman videos)
- Jeju dialect that taste and stylish data (data collected from the book 'Jeju Tongue Taste and Prize')
- Data even if it passes off, even if it passes, it collects data from the book 'Even if it is gone')
- 2018 Jeju Language Oral Materials Collection (Collected for Evaluation)
3. Model learning
3-1. Model related
I learned in a way to bring in the pre-learning model and Fine-Tuning .
Pre -learning model used to develop translation models:
Pre -learning model selection criteria
- Is it the right model for translation?
- Is it learned in Korean?
- Is the model capacity so big and the learning speed is fast?
Models that have been considered but not selected:
- T5 (There is a problem with too long learning time)
- Jebert (performance was not satisfactory)
3-2. Learning method
Learning methodology
- Source-> Learning in Target format
- Prior to entering the sentence, adding [Jeju] or [Standard] tokens to specify the direction of translation and learning together
- Using the Dataset of the DataSets package, converting it to an optimized form for language model learning
Main parameter settings
- MAX_LENGTH: 64
- batch_size: 32
- Transing_rate: At first, starting from 2E-5 and learning progresses gradually reduced
- EPOCHS: 3
? 4. Main achievements
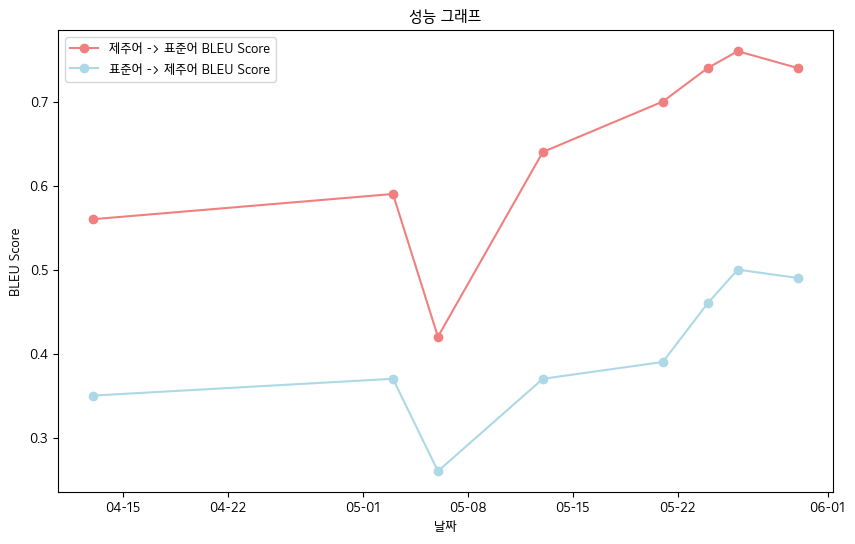
- Final BLEU Score -Jeju Language Oral Data Book Data Standards
- Jeju language-> standard language: 0.76
- Standard language-> Jeju language: 0.5
- BLEU Score Performance Table
| date | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| Jeju language-> standard language bleu score | 0.56 | 0.59 | 0.42 | 0.64 | 0.70 | 0.74 | 0.76 | 0.74 |
| Standard language-> Jeju Bleu Score | 0.35 | 0.37 | 0.26 | 0.37 | 0.39 | 0.46 | 0.50 | 0.49 |
- Overall, we recorded the BLEU Score .
? 5. Future plans
- Preliminary processing through additional data collection and grammatic micro -adjustment to secure quality data
- Improvement of the ability to recognize the accent of the voice recognition model
- Web implementation and mobile app development plan
? 6. Reference
- Data source
- Korean dialect ignition data (provided by AI-HUB): https://www.aihub.or.kr/aihubdata/data/View.do?curmenu=115&topmenu
- Middle and older Korean dialect data (AI-HUB): https://www.aihub.or.kr/aihubdata/data/VIEW.DO?Curmenu=115&topmenu
- Kakao JIT Jeju Tongue Data (see Kakaobrane GitHub): https://github.com/kakaobrain/jejuo
- Living Living Side Data (see Jeju Language Preliminary): https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- Model source
- Kobart Hugging Face: https://huggingFace.co/gogamza/kobart-base-v2
- Whisper Hugging Face: https://huggingFace.co/openai/whisper-large-v2
- Kobart github: https://github.com/skt-ai/kobart


