؟ لغة jeju ، اللغة القياسية مشروع إنشاء نموذج الترجمة الصوتية اثنين
استخدام النموذج
import torch
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
## Set up the device (GPU or CPU)
device = torch . device ( "cuda" if torch . cuda . is_available () else "cpu" )
## Load the tokenizer and model
tokenizer = AutoTokenizer . from_pretrained ( "Junhoee/Kobart-Jeju-translation" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Junhoee/Kobart-Jeju-translation" ). to ( device )
## Set up the input text
## 문장 입력 전에 방향에 맞게 [제주] or [표준] 토큰을 입력 후 문장 입력
input_text = "[표준] 안녕하세요"
## Tokenize the input text
input_ids = tokenizer ( input_text , return_tensors = "pt" , padding = True , truncation = True ). input_ids . to ( device )
## Generate the translation
outputs = model . generate ( input_ids , max_length = 64 )
## Decode and print the output
decoded_output = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( "Model Output:" , decoded_output )
؟ دوري
- إنشاء مجموعة البيانات
- جمع مجموعات بيانات Jeju-Standard وإعدادها لمجموعة بيانات جديدة (مجموعة بيانات)
- جمع البيانات مثل ai-hub ، github ، إلخ.
- تصميم منطق نموذج الترجمة
- ضبط جيد كنموذج كوبارت
- من بين نماذج النص text2tex باللغة الكورية باللغة الكورية ، يعد Kobart أفضل وأسرع نموذج.
- في عملية تصميم اثنين من المنطقين ، يدخل الرموز [Jeju] و [Standard] أمام الجملة لجعل النموذج سهل الفهم (BLEU درجة 0.5-> 0.7 ، حتى 1 معيار)
- نظرًا لعدم وجود ذاكرة الوصول العشوائي ، تم تعلم 700000 بيانات فقط ، ولكن تم تغيير طريقة تنسيق مجموعة البيانات من Float16 إلى UNIT16 لحل نقص الذاكرة (ذاكرة GPU ، حفظ الموارد)
1. إدخال المشروع
؟ عضو فريق
- فيتامين 12: زعيم ، لي سيو -هيون ، لي يرين
- فيتامين 13: كيم يون -يونج ، كيم جاي -جيوم ، لي هيونغ -سيوك
؟ فترة
؟ ️ الموضوع
- إنشاء لهجة jeju ونموذج ترجمة ثنائي الاتجاه اللغوي القياسي
هدف
- نود الترويج لفهم لهجات جيجو والمساهمة في الحفاظ على ثقافة جيجو.
- نحن نشجع التواصل السلس مع المواطنين في جيجو.
- نقوم بتطوير نموذج ترجمة مكونين يربطان لهجة Jeju واللغة القياسية الكورية.
- تنفيذ التعرف على الصوت وواجهة المستخدم.
2. جمع البيانات
3. التعلم النموذج
3-1. النموذج المتعلق
لقد تعلمت بطريقة لجلب نموذج ما قبل التعلم والضبط .
نموذج ما قبل التعليم المستخدم لتطوير نماذج الترجمة:
معايير اختيار نموذج ما قبل التعلم
- هل هو النموذج الصحيح للترجمة؟
- هل هي تعلمت باللغة الكورية؟
- هل سعة النموذج كبيرة جدًا وسرعة التعلم سريعة؟
النماذج التي تم النظر فيها ولكن لم يتم اختيارها:
- T5 (هناك مشكلة في وقت التعلم الطويل)
- جيبرت (لم يكن الأداء مرضيًا)
3-2. طريقة التعلم
منهجية التعلم
- المصدر-> التعلم في التنسيق المستهدف
- قبل إدخال الجملة ، إضافة الرموز المميزة [jeju] أو [قياسية] لتحديد اتجاه الترجمة والتعلم معًا
- باستخدام مجموعة البيانات الخاصة بحزمة مجموعات البيانات ، وتحويلها إلى نموذج محسّن لمعرفة نموذج اللغة
إعدادات المعلمة الرئيسية
- max_length: 64
- Batch_size: 32
- transing_rate: في البداية ، بدءًا من 2e-5 ويتقدم التعلم تدريجياً
- الحقبة: 3
؟ 4. الإنجازات الرئيسية
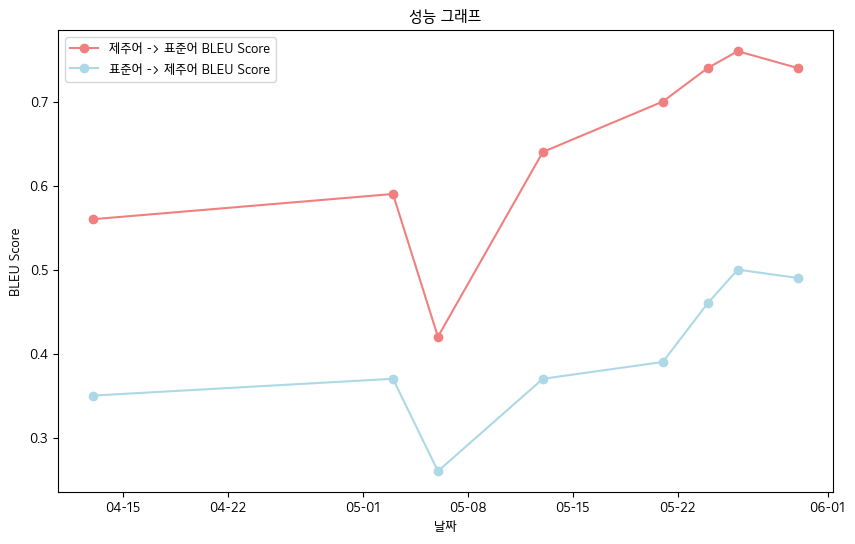
- النتيجة النهائية لدرجة Bleu -معايير بيانات دفتر البيانات عن طريق الفم Jeju
- لغة jeju-> اللغة القياسية: 0.76
- اللغة القياسية-> لغة jeju: 0.5
- جدول أداء النتيجة Bleu
| تاريخ | 04-13 | 05-03 | 05-06 | 05-13 | 05-21 | 05-24 | 05-26 | 05-30 |
|---|
| jeju language-> نقاط لغة بليو القياسية | 0.56 | 0.59 | 0.42 | 0.64 | 0.70 | 0.74 | 0.76 | 0.74 |
| اللغة القياسية-> نقاط Jeju Bleu | 0.35 | 0.37 | 0.26 | 0.37 | 0.39 | 0.46 | 0.50 | 0.49 |
- وعموما ، سجلنا درجة Bleu .
تنفيذ الواجهة
وظيفة التعرف على الصوت
- Stt
- استلم نماذج الهمس من معانقة الوجه والمضي قدما في الضبط
- تحويل لغة jeju إلى رسالة نصية وتحويلها إلى نص
- TTS
- استلم Glos TTS ، نموذج Hifigan من معانقة الوجه والمضي قدما في الضبط
- حاولت التعبير عن الصوت في جيجو ، لكنني فشلت ...
- التعبير بدلاً من صوت اللغة القياسي (باستخدام GTTS)
؟ 5. الخطط المستقبلية
- المعالجة الأولية من خلال جمع البيانات الإضافية والتعديل الدقيق النحوي لتأمين بيانات الجودة
- تحسين القدرة على التعرف على لهجة نموذج التعرف على الصوت
- خطة تنفيذ الويب وخطة تطوير تطبيقات الهاتف المحمول
؟ 6. المرجع
- مصدر البيانات
- بيانات الإشعال الكورية لهجة الكورية (المقدمة من AI-hub): https://www.aihub.or.kr/aihubdata/data/view.do؟curmenu=115&topmenu
- بيانات اللهجة الكورية المتوسطة والأكبر (AI-HUB): https://www.aihub.or.kr/aihubdata/data/view.do؟curmenu=115&topmenu
- بيانات لسان Kakao Jit Jeju (انظر Kakaobrane Github): https://github.com/kakaobrain/jejuo
- بيانات جانب المعيشة المعيشة (انظر jeju لغة أولية): https://www.jeju.go.kr/culture/dialect/lifedialect.htm
- مصدر النموذج
- Kobart Hugging Face: https://huggingface.co/gogamza/kobart-base-v2
- الوجه الوجه المعانقة: https://huggingface.co/openai/whisper-large-v2
- Kobart Github: https://github.com/skt-ai/kobart


