vits mandarin biaobei
1.0.0
在最近的論文中,我們提出了VIT:對端到端文本到語音的對抗性學習的條件變異自動編碼器。
已經提出了一些近期的端到端文本到語音(TTS)模型,該模型已提出了單階段訓練和並行抽樣,但它們的樣品質量與兩個階段TTS系統的質量不符。在這項工作中,我們提出了一種並行的端到端TTS方法,該方法比當前的兩個階段模型生成更自然的音頻。我們的方法採用了通過標準化流量和對抗性訓練過程增強的變異推理,從而提高了生成建模的表現力。我們還提出了一個隨機持續時間預測因子,以通過輸入文本中的各種節奏合成語音。通過對潛在變量的不確定性建模和隨機持續時間的預測指標,我們的方法表達了自然的一對一關係,其中可以通過不同的音調和節奏以多種方式使用文本輸入。單個發言人數據集對LJ語音的主觀人類評估(平均意見分數或MOS)表明,我們的方法的表現優於最好的公開可用的TTS系統,並實現了與地面真相相比的MOS。
訪問我們的演示以獲取音頻樣本。
我們還提供了驗證的模型。
**更新註:感謝Rishikesh(ऋषिकेश),我們的Interactive TTS演示現已在COLAB筆記本上找到。
| 訓練 | 推理 |
|---|---|
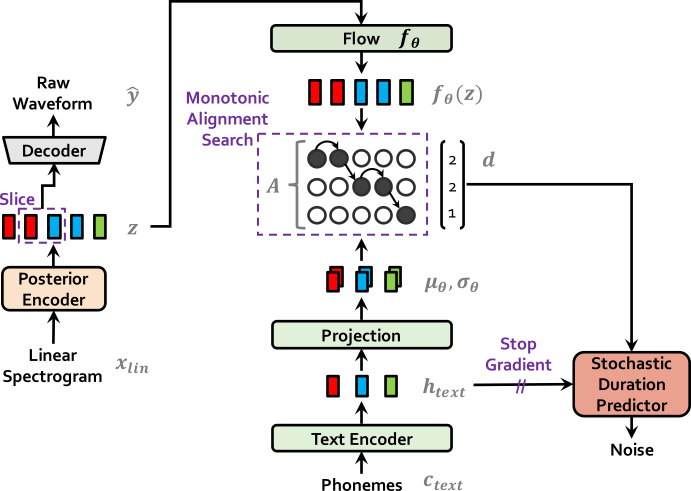 | 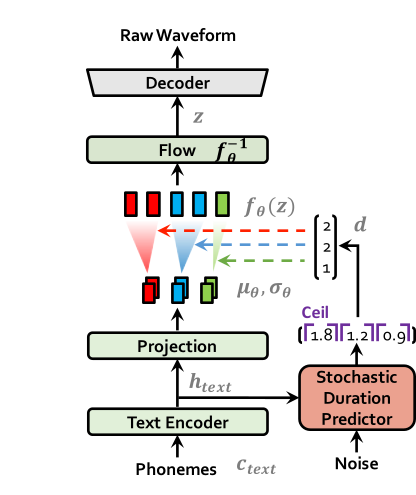 |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_base請參閱推理。 IPYNB


