vits mandarin biaobei
1.0.0
ในบทความล่าสุดของเราเราเสนอ VITS: Autoencoder แบบแปรผันตามเงื่อนไขพร้อมการเรียนรู้ที่เป็นปฏิปักษ์สำหรับการพูดแบบข้อความถึงการพูด
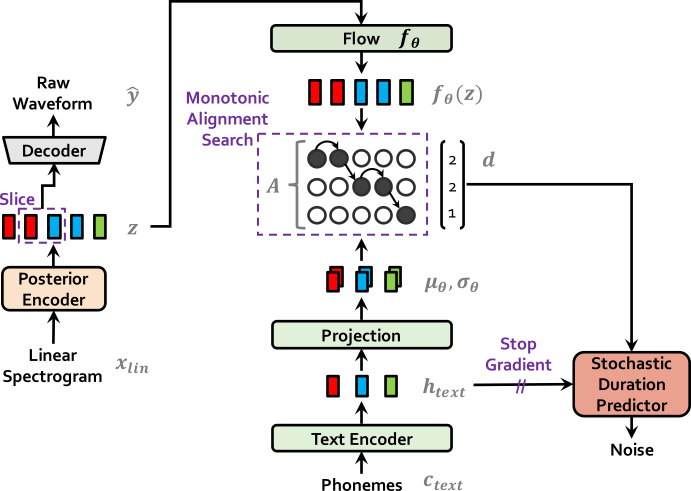
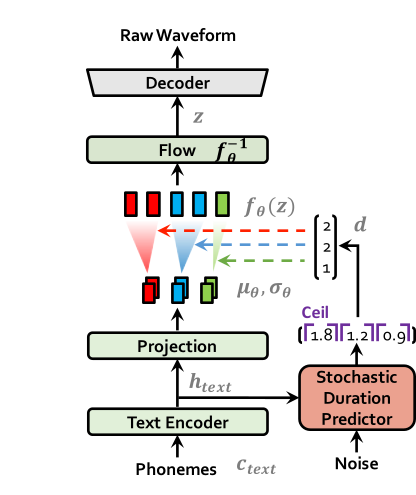
รุ่น text-to-end-to-speech (TTS) ล่าสุดหลายรุ่นที่เปิดใช้งานการฝึกอบรมขั้นตอนเดียวและการสุ่มตัวอย่างแบบขนานได้รับการเสนอ แต่คุณภาพตัวอย่างของพวกเขาไม่ตรงกับระบบ TTS สองขั้นตอน ในงานนี้เรานำเสนอวิธี TTS แบบ end-to-end แบบขนานที่สร้างเสียงที่เป็นธรรมชาติมากกว่ารุ่นสองขั้นตอนปัจจุบัน วิธีการของเราใช้การอนุมานแบบแปรผันเพิ่มขึ้นด้วยการไหลของการไหลเป็นมาตรฐานและกระบวนการฝึกอบรมที่เป็นปฏิปักษ์ซึ่งช่วยเพิ่มพลังการแสดงออกของการสร้างแบบจำลองการกำเนิด นอกจากนี้เรายังเสนอตัวทำนายระยะเวลาสุ่มเพื่อสังเคราะห์คำพูดด้วยจังหวะที่หลากหลายจากข้อความอินพุต ด้วยการสร้างแบบจำลองความไม่แน่นอนเหนือตัวแปรแฝงและตัวทำนายระยะเวลาสุ่มวิธีการของเราเป็นการแสดงออกถึงความสัมพันธ์แบบหนึ่งต่อหลาย ๆ ซึ่งสามารถพูดได้หลายวิธีด้วยเสียงและจังหวะที่แตกต่างกัน การประเมินผลของมนุษย์แบบอัตนัย (หมายถึงคะแนนความคิดเห็นหรือ MOS) ในคำพูด LJ ซึ่งเป็นชุดข้อมูลลำโพงเดียวแสดงให้เห็นว่าวิธีการของเรามีประสิทธิภาพสูงกว่าระบบ TTS ที่เปิดเผยต่อสาธารณะที่ดีที่สุดและบรรลุ MOS เทียบได้กับความจริงพื้นฐาน
เยี่ยมชมตัวอย่างของเราสำหรับตัวอย่างเสียง
นอกจากนี้เรายังให้แบบจำลองที่ผ่านการฝึกอบรม
** อัปเดตหมายเหตุ: ขอบคุณ Rishikesh (ऋषिकेश) การสาธิต TTS แบบโต้ตอบของเราพร้อมใช้งานใน Notebook Colab
| เข้าร่วมการฝึกอบรม | เข้าที่การอนุมาน |
|---|---|
 |  |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_baseดู inference.ipynb


