vits mandarin biaobei
1.0.0
Dans notre article récent, nous proposons des VITS: Autoencoder variationnel conditionnel avec apprentissage contradictoire pour le texte à la vitesse à la disposition de bout en bout.
Plusieurs modèles récents de texte à dispection de bout en bout (TTS) permettant une formation à un étage et un échantillonnage parallèle ont été proposés, mais leur qualité d'échantillon ne correspond pas à celle des systèmes TTS à deux étapes. Dans ce travail, nous présentons une méthode TTS de bout en bout parallèle qui génère un audio de sondage plus naturel que les modèles actuels en deux étapes. Notre méthode adopte l'inférence variationnelle augmentée avec des flux de normalisation et un processus de formation contradictoire, ce qui améliore la puissance expressive de la modélisation générative. Nous proposons également un prédicteur de durée stochastique pour synthétiser la parole avec divers rythmes à partir du texte d'entrée. Avec la modélisation de l'incertitude sur les variables latentes et le prédicteur de la durée stochastique, notre méthode exprime la relation naturelle un à plusieurs dans laquelle une entrée de texte peut être parlée de plusieurs manières avec différentes hauteurs et rythmes. Une évaluation humaine subjective (score d'opinion moyen, ou MOS) sur le discours LJ, un ensemble de données de haut-parleur, montre que notre méthode surpasse les meilleurs systèmes TTS accessibles au public et atteint un MOS comparable à la vérité au sol.
Visitez notre démo pour des échantillons audio.
Nous fournissons également les modèles pré-entraînés.
** Mise à jour Remarque: Grâce à Rishikesh (ऋषिकेश), notre démo TTS interactive est maintenant disponible sur Colab Notebook.
| VITS À LA FORMATION | Vit à l'inférence |
|---|---|
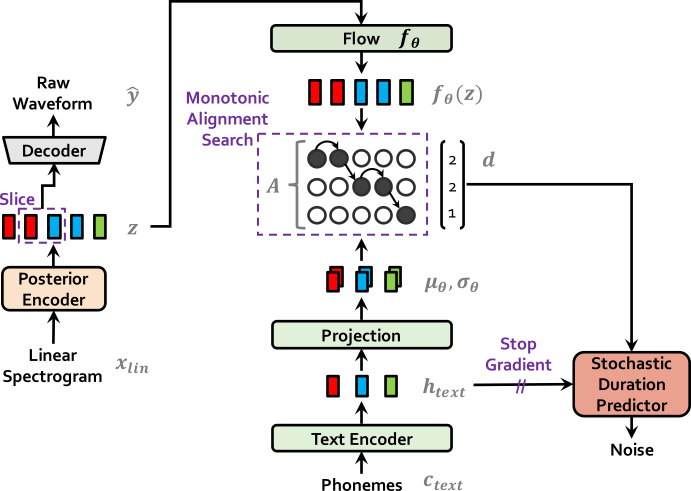 | 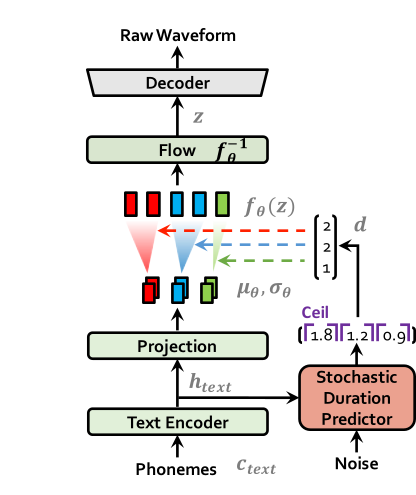 |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_baseVoir inférence.Ipynb


