vits mandarin biaobei
1.0.0
Em nosso artigo recente, propomos Vits: AutoEncoder variacional condicional com aprendizado adversário para o texto a ponta-a-ponta.
Vários modelos recentes de texto para falar de ponta a ponta (TTS) que permitem treinamento em estágio único e amostragem paralela foram propostos, mas sua qualidade de amostra não corresponde à dos sistemas TTS em dois estágios. Neste trabalho, apresentamos um método TTS de ponta a ponta paralelo que gera áudio mais natural do que os modelos atuais de dois estágios. Nosso método adota a inferência variacional aumentada com os fluxos normalizados e um processo de treinamento adversário, o que melhora o poder expressivo da modelagem generativa. Também propomos um preditor de duração estocástica para sintetizar a fala com diversos ritmos do texto de entrada. Com a modelagem de incerteza sobre variáveis latentes e o preditor de duração estocástica, nosso método expressa a relação natural de um a muitos, na qual uma entrada de texto pode ser falada de várias maneiras com diferentes arremessos e ritmos. Uma avaliação humana subjetiva (pontuação média de opinião, ou MOS) no discurso de LJ, um conjunto de dados de alto -falante, mostra que nosso método supera os melhores sistemas TTS publicamente disponíveis e atinge um MOS comparável à verdade fundamental.
Visite nossa demonstração para amostras de áudio.
Também fornecemos os modelos pré -treinados.
** Nota de atualização: graças a Rishikesh (ऋषिकेश ऋषिकेश), nossa demonstração interativa do TTS está agora disponível no Colab Notebook.
| Vits no treinamento | Vits em inferência |
|---|---|
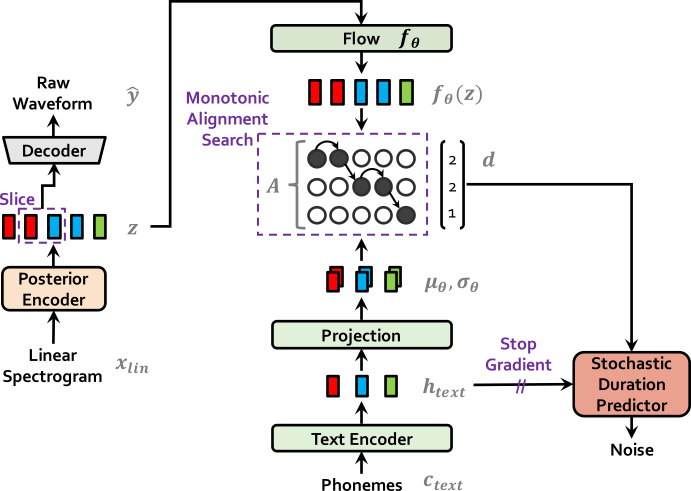 | 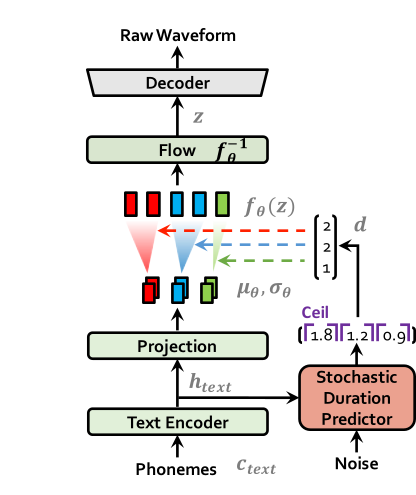 |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_baseVeja inference.ipynb


