vits mandarin biaobei
1.0.0
In unserem jüngsten Artikel schlagen wir Vits vor: bedingter Variationsautoencoder mit kontroversem Lernen für End-to-End-Text-zu-Sprach.
Es wurden mehrere aktuelle Modelle für End-to-End-Text-zu-Sprache (TTS) ein einstufiges Training und parallele Stichproben vorgeschlagen, ihre Stichprobenqualität entspricht jedoch nicht der von zweistufigen TTS-Systemen. In dieser Arbeit präsentieren wir eine parallele End-to-End-TTS-Methode, die mehr natürliche Audio als aktuelle zweistufige Modelle erzeugt. Unsere Methode übernimmt eine durch Normalisierungsströme und eines kontroversen Trainingsprozesses verstärkte Variationsinferenz, die die ausdrucksstarke Leistung der generativen Modellierung verbessert. Wir schlagen auch einen stochastischen Dauer -Prädiktor vor, um Sprache mit verschiedenen Rhythmen aus Eingabetxt zu synthetisieren. Mit der Unsicherheitsmodellierung über latente Variablen und dem stochastischen Dauerprädiktor drückt unsere Methode die natürliche Eins-zu-Viele-Beziehung aus, in der ein Texteingang auf verschiedene Arten mit unterschiedlichen Tonhöhen und Rhythmen gesprochen werden kann. Eine subjektive menschliche Bewertung (mittlere Meinungsbewertung oder MOS) in der LJ -Sprache, ein einzelner Sprecher -Datensatz, zeigt, dass unsere Methode die besten öffentlich verfügbaren TTS -Systeme übertrifft und eine MOS erreicht, die mit der Grundwahrheit vergleichbar ist.
Besuchen Sie unsere Demo für Audio -Beispiele.
Wir stellen auch die vorbereiteten Modelle zur Verfügung.
** UPDATE HINWEIS: Dank Rishikesh (ऋषिकेश) ist unsere interaktive TTS -Demo jetzt auf Colab Notebook verfügbar.
| Vits beim Training | Vits bei Inferenz |
|---|---|
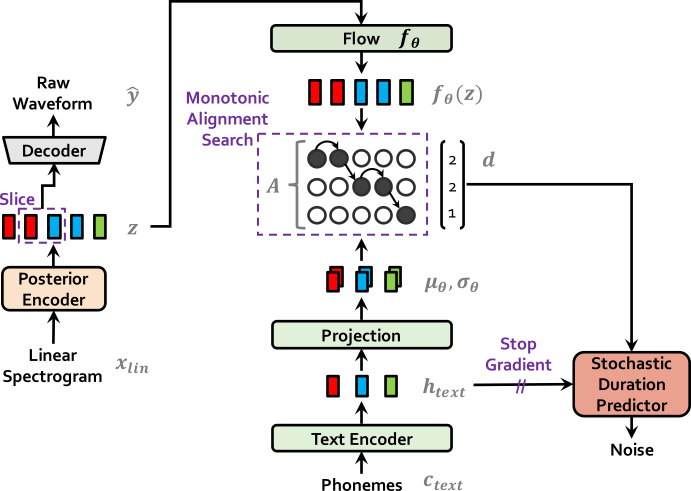 | 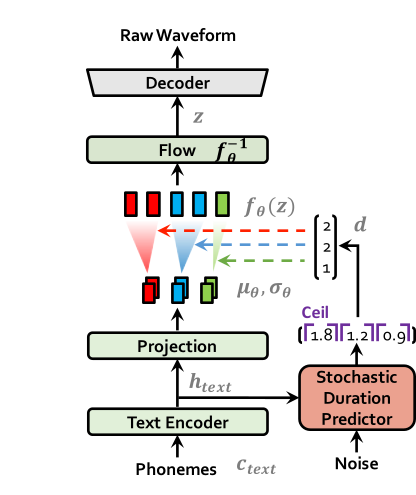 |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 Link zum Dataset -Ordner um oder erstellen # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_baseSiehe Inferenz.ipynb


