vits mandarin biaobei
1.0.0
最近の論文では、vitsを提案します。エンドツーエンドのテキストからスピーチのための敵対的な学習を備えた条件付き変動自動エンコーダーです。
シングルステージトレーニングと並列サンプリングを有効にする最近のエンドツーエンドのテキスト(TTS)モデルが提案されていますが、そのサンプル品質は2段階のTTSシステムの品質と一致しません。この作業では、現在の2段階モデルよりも自然なサウンドオーディオを生成する並列エンドツーエンドTTSメソッドを提示します。私たちの方法は、正規化フローと敵対的なトレーニングプロセスで増強された変動推論を採用し、生成モデリングの表現力を向上させます。また、入力テキストからの多様なリズムを使用した音声を合成する確率的持続時間予測子を提案します。潜在変数に対する不確実性モデリングと確率的持続時間予測因子により、私たちの方法は、異なるピッチとリズムでテキスト入力を複数の方法で話すことができる自然な1対多くの関係を表します。 LJスピーチでの主観的な人間の評価(平均意見スコア、またはMOS)、単一のスピーカーデータセットは、この方法が最も公開されているTTSシステムを上回り、Ground Truthに匹敵するMOを達成することを示しています。
オーディオサンプルについては、デモにアクセスしてください。
また、前提条件のモデルも提供します。
**更新メモ:Rishikesh(ऋषिकेश)のおかげで、インタラクティブなTTSデモがColabノートブックで入手可能になりました。
| トレーニングでのvits | 推論でのvits |
|---|---|
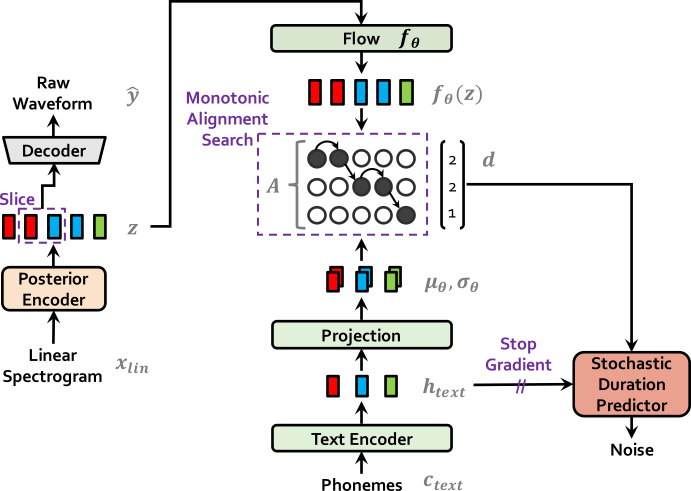 | 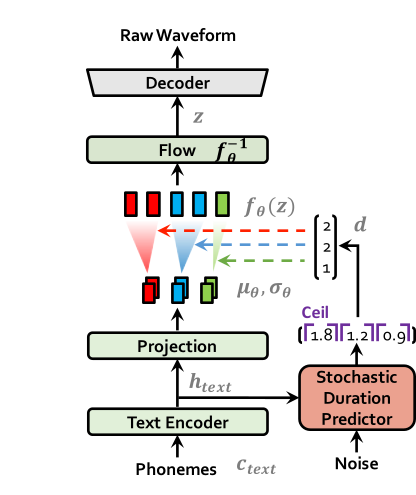 |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1変更または作成します。ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_baseInference.ipynbを参照してください


