vits mandarin biaobei
1.0.0
在最近的论文中,我们提出了VIT:对端到端文本到语音的对抗性学习的条件变异自动编码器。
已经提出了一些近期的端到端文本到语音(TTS)模型,该模型已提出了单阶段训练和并行抽样,但它们的样品质量与两个阶段TTS系统的质量不符。在这项工作中,我们提出了一种并行的端到端TTS方法,该方法比当前的两个阶段模型生成更自然的音频。我们的方法采用了通过标准化流量和对抗性训练过程增强的变异推理,从而提高了生成建模的表现力。我们还提出了一个随机持续时间预测因子,以通过输入文本中的各种节奏合成语音。通过对潜在变量的不确定性建模和随机持续时间的预测指标,我们的方法表达了自然的一对一关系,其中可以通过不同的音调和节奏以多种方式使用文本输入。单个发言人数据集对LJ语音的主观人类评估(平均意见分数或MOS)表明,我们的方法的表现优于最好的公开可用的TTS系统,并实现了与地面真相相比的MOS。
访问我们的演示以获取音频样本。
我们还提供了验证的模型。
**更新注:感谢Rishikesh(ऋषिकेश),我们的Interactive TTS演示现已在COLAB笔记本上找到。
| 训练 | 推理 |
|---|---|
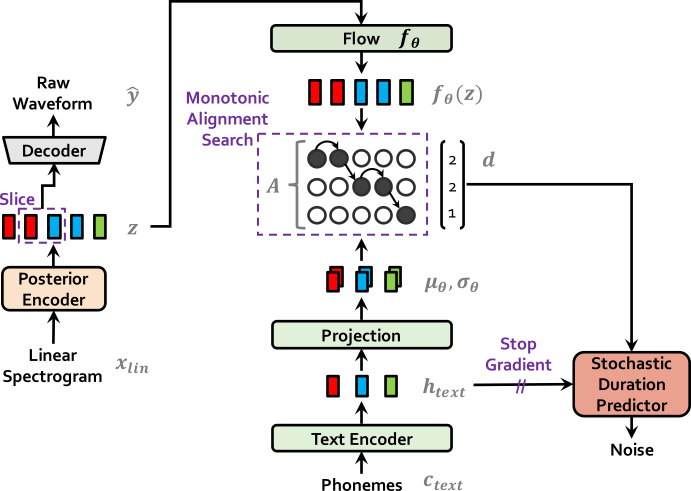 | 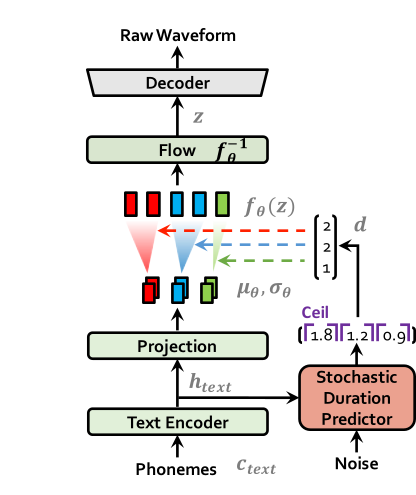 |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_base请参阅推理。IPYNB


