vits mandarin biaobei
1.0.0
최근 논문에서, 우리는 vits를 제안합니다 : 엔드 투 엔드 텍스트 음성 연사를위한 적대적 학습을 가진 조건부 변형 자동 코더.
단일 단계 훈련 및 병렬 샘플링을 가능하게하는 최근의 여러 엔드 투 엔드 텍스트 음성 (TTS) 모델이 제안되었지만 샘플 품질은 2 단계 TTS 시스템의 샘플 품질과 일치하지 않습니다. 이 작업에서는 현재 2 단계 모델보다 더 자연스러운 사운드 오디오를 생성하는 병렬 엔드 투 엔드 TTS 방법을 제시합니다. 우리의 방법은 정규화 흐름과 적대적 훈련 과정으로 보강 된 변형 추론을 채택하여 생성 모델링의 표현력을 향상시킵니다. 또한 입력 텍스트의 다양한 리듬으로 음성을 합성하기 위해 확률 론적 기간 예측 변수를 제안합니다. 잠재 변수에 대한 불확실성 모델링과 확률 기간 예측 변수를 통해, 우리의 방법은 다른 피치와 리듬으로 여러 가지 방법으로 텍스트 입력을 할 수있는 자연스러운 일대일 관계를 표현합니다. 단일 스피커 데이터 세트 인 LJ Speech에 대한 주관적인 인간 평가 (평균 의견 점수 또는 MO)는 우리의 방법이 공개적으로 가장 공개적으로 이용 가능한 TTS 시스템을 능가하고 근거 진실과 비슷한 MOS를 달성한다는 것을 보여줍니다.
오디오 샘플은 데모를 방문하십시오.
우리는 또한 사전 각인 모델을 제공합니다.
** 업데이트 참고 : Rishikesh (ऋषिकेश) 덕분에 대화식 TTS 데모는 이제 Colab Notebook에서 사용할 수 있습니다.
| 훈련시 vits | 추론에 vits |
|---|---|
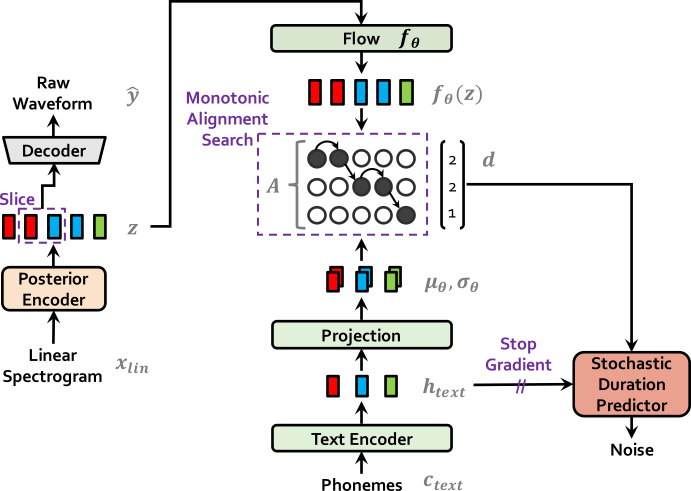 | 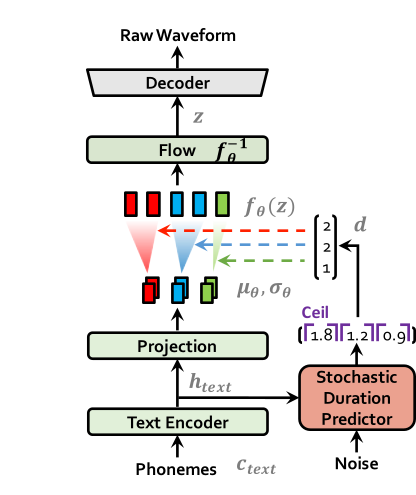 |
apt-get install espeak 해야 할 수도 있습니다.ln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_base추론 .ipynb를 참조하십시오


