vits mandarin biaobei
1.0.0
في ورقتنا الحديثة ، نقترح حالات: Autoencoder التباين الشرطي مع التعلم العدائي للرسائل النصية من طرف إلى طرف.
تم اقتراح العديد من نماذج النص إلى الخطوط إلى الخطية (TTS) التي تتيح التدريب أحادي المرحلة وأخذ عينات متوازية ، ولكن جودة عينةها لا تتطابق مع أنظمة TTS على مرحلتين. في هذا العمل ، نقدم طريقة TTS متوازية من طرف إلى طرف تولد صوتًا أكثر طبيعية من النماذج الحالية على مرحلتين. تعتمد طريقتنا الاستدلال المتغير مع زيادة التدفقات التطبيع وعملية التدريب العدواني ، مما يحسن القوة التعبيرية للنمذجة التوليدية. نقترح أيضًا تنبؤًا مدة عشوائية لتوليف الكلام مع إيقاعات متنوعة من نص الإدخال. مع نمذجة عدم اليقين على المتغيرات الكامنة والتنبؤ بالمدة العشوائية ، تعبر طريقتنا عن العلاقة الطبيعية التي يمكن أن يتم فيها التحدث بمدخلات النص بطرق متعددة بطرق وإيقاعات مختلفة. يوضح التقييم الإنساني الذاتي (متوسط درجة الرأي ، أو MOS) في خطاب LJ ، وهو مجموعة بيانات من سماعات واحدة ، أن طريقتنا تتفوق على أفضل أنظمة TTS متوفرة للجمهور ويحقق MOS مماثلة للحقيقة الأرضية.
قم بزيارة العرض التوضيحي الخاص بنا لعينات الصوت.
نحن نقدم أيضا النماذج المسبق.
** تحديث ملاحظة: بفضل Rishikesh (ऋषिकेश) ، يتوفر الآن Demo التفاعلي TTS على دفتر Colab Notebook.
| حركات في التدريب | حالات في الاستدلال |
|---|---|
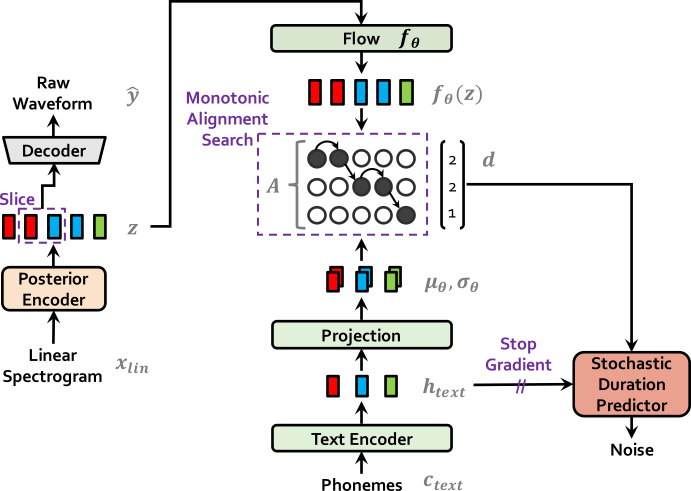 | 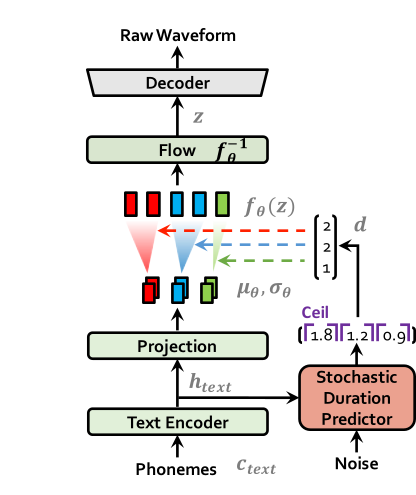 |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_baseانظر الاستدلال


