vits mandarin biaobei
1.0.0
En nuestro artículo reciente, proponemos VIT: autoencoder de variacional condicional con aprendizaje adversario para texto a voz de extremo a extremo.
Se han propuesto varios modelos recientes de texto a discurso (TTS) de extremo a extremo que permiten entrenamiento de una sola etapa y muestreo paralelo, pero su calidad de muestra no coincide con la de los sistemas TTS de dos etapas. En este trabajo, presentamos un método TTS de extremo a extremo paralelo que genera un audio de sonido más natural que los modelos actuales de dos etapas. Nuestro método adopta una inferencia variacional aumentada con flujos de normalización y un proceso de entrenamiento adversario, lo que mejora el poder expresivo del modelado generativo. También proponemos un predictor de duración estocástica para sintetizar el habla con diversos ritmos del texto de entrada. Con el modelado de incertidumbre sobre las variables latentes y el predictor de duración estocástica, nuestro método expresa la relación natural de uno a muchos en la que se puede hablar una entrada de texto de múltiples maneras con diferentes lanzamientos y ritmos. Una evaluación humana subjetiva (puntaje de opinión media, o MOS) en el discurso LJ, un conjunto de datos de oradores único, muestra que nuestro método supera a los mejores sistemas TTS disponibles públicamente y logra un MOS comparable a la verdad terrestre.
Visite nuestra demostración para muestras de audio.
También proporcionamos los modelos previos a la aparición.
** Nota de actualización: Gracias a Rishikesh (ऋषिकेश), nuestra demostración interactiva de TTS ya está disponible en Colab Notebook.
| Vits en el entrenamiento | Vits a inferencia |
|---|---|
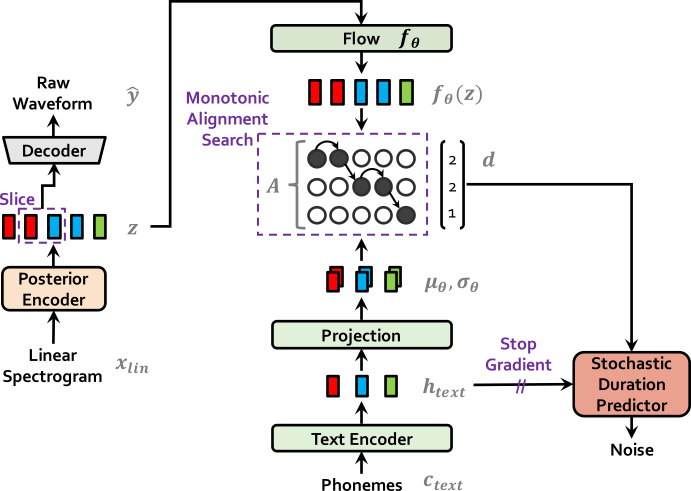 | 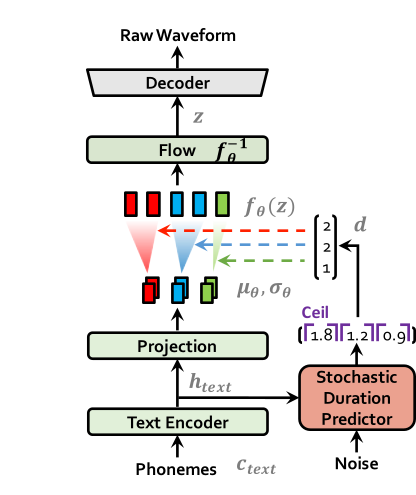 |
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt # LJ Speech
python train.py -c configs/ljs_base.json -m ljs_base
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_baseVer inferencia.ipynb


