AdaSpeech
1.0.0
非正式的Pytorch Adaspeech實施。
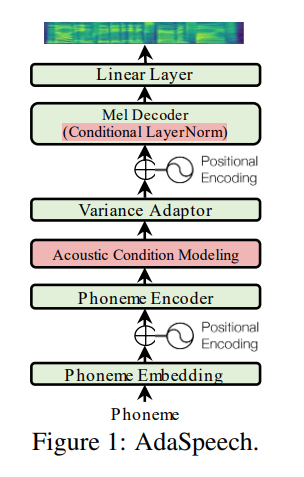
Utterance level encoder和Phoneme level encoder而不是條件層規範(這是Adaspeech紙的靈魂),它決定了Adaspeech的適應性,但我的重點是改善FastSpeech 2聲學概括而不是適應性。 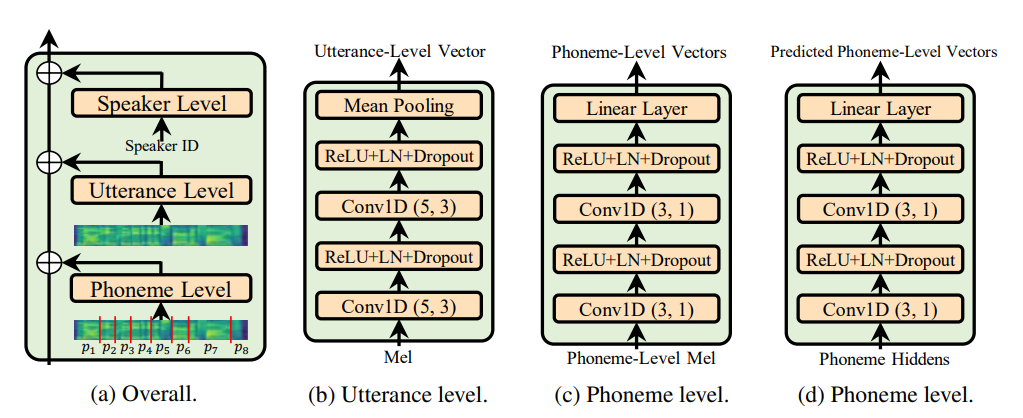
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
}所有代碼以Python 3.6.2編寫。
在安裝Pytorch之前,請通過運行以下命令來檢查您的CUDA版本:
nvcc --version
pip install torch torchvision
在此存儲庫中,我使用了pytorch 1.6.0用於torch.bucketize功能,這在pytorch的先前版本中不存在。
pip install -r requirements.txt
tensorboard version 1.14.0分別使用受支持的tensorflow (1.14.0) filelists文件夾包含MFA(Motreal Force Aligner)處理的LJSpeech數據集文件,因此您無需將文本與LJSpeech數據集的音頻(用於提取持續時間)對齊。對於其他數據集,請在此處遵循指令。對於其他預處理運行以下命令:
python nvidia_preprocessing.py -d path_of_wavs
查找F0和能量的最小和最大
python compute_statistics.py
在hparams.py中更新以下內容,按min和最大的f0和能量更新
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


