AdaSpeech
1.0.0
Implementasi Pytorch tidak resmi dari Adaspeech.
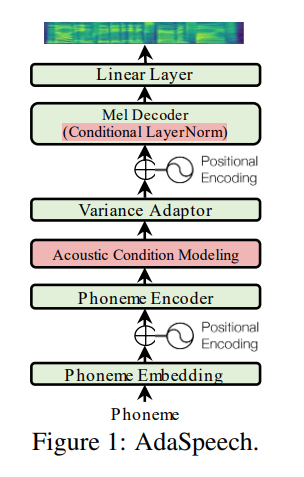
Utterance level encoder dan Phoneme level encoder bukan kondisi norma lapisan (yang merupakan jiwa dari kertas adaspeech), itu definely membatasi sifat adaptif adaspeech tetapi fokus saya adalah untuk meningkatkan generalisasi akustik fastspeech 2 daripada adaptasi. 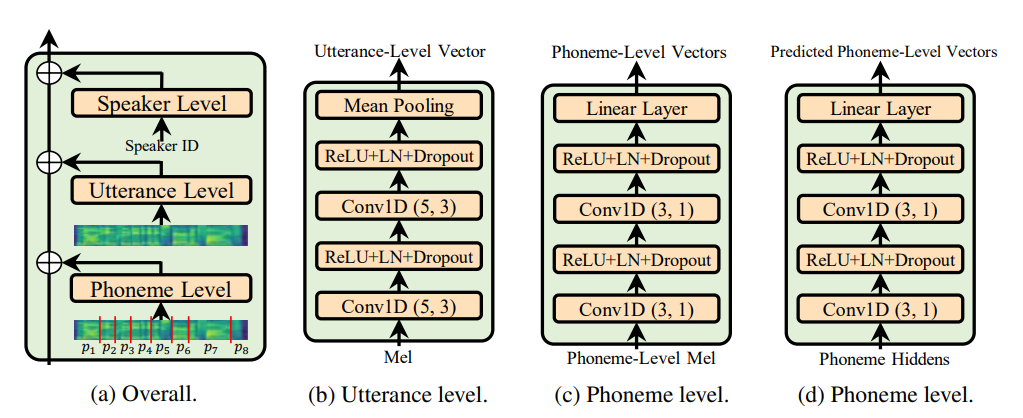
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
} Semua kode yang ditulis dalam Python 3.6.2 .
Sebelum menginstal pytorch, silakan periksa versi CUDA Anda dengan menjalankan perintah berikut:
nvcc --version
pip install torch torchvision
Dalam repo ini saya telah menggunakan pytorch 1.6.0 untuk fitur torch.bucketize yang tidak ada dalam versi Pytorch sebelumnya.
pip install -r requirements.txt
tensorboard version 1.14.0 Seperatly dengan tensorflow (1.14.0) Folder filelists berisi MFA (Motreal Force Aligner) yang diproses file dataset LJSPEECH sehingga Anda tidak perlu menyelaraskan teks dengan audio (untuk durasi ekstrak) untuk dataset LJSPEECH. Untuk dataset lain, ikuti instruksi di sini. Untuk perintah pengikut menjalankan pra-pemrosesan lainnya:
python nvidia_preprocessing.py -d path_of_wavs
Untuk menemukan min dan max f0 dan energi
python compute_statistics.py
Perbarui yang berikut di hparams.py oleh min dan max f0 dan energi
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


