AdaSpeech
1.0.0
Неофициальная внедрение Pytorch Adaspeech.
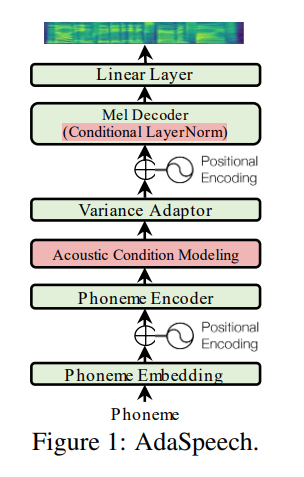
Utterance level encoder и Phoneme level encoder а не норму слоя условия (которая является душой статьи статьи), он определенно ограничивает адаптивную природу Adaspeech, но я сосредоточен на улучшении акустического обобщения 2 -го сыска, а не адаптации. 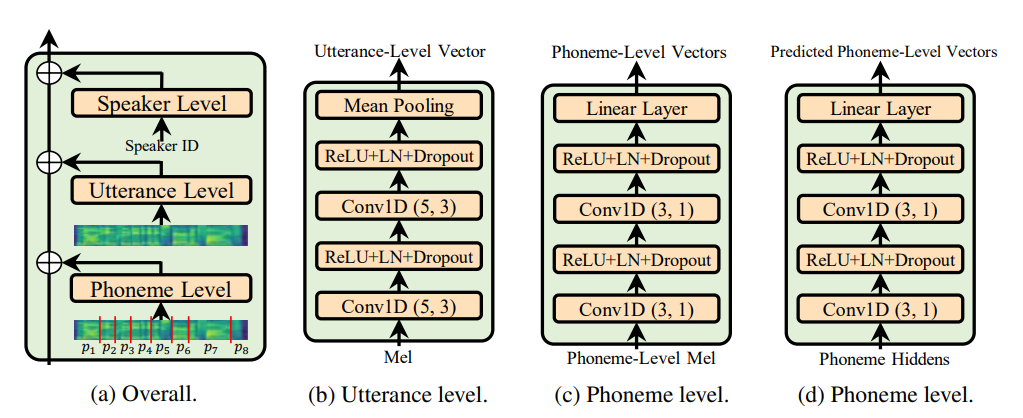
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
} Весь код, написанный в Python 3.6.2 .
Перед установкой Pytorch, пожалуйста, проверьте свою версию CUDA, выполнив следующую команду:
nvcc --version
pip install torch torchvision
В этом репо я использовал pytorch 1.6.0 для функции torch.bucketize , которая не присутствует в предыдущих версиях Pytorch.
pip install -r requirements.txt
tensorboard version 1.14.0 Seperatly с поддерживаемым tensorflow (1.14.0) Папка filelists содержит MFA (MotReal Force Aligner), обработанные файлы набора данных LJSPEECH, поэтому вам не нужно выравнивать текст с аудио (для продолжительности извлечения) для набора данных LJSPEECH. Для другого набора данных следуйте инструкции здесь. Для другого предварительного обработки выполнения следующей команды:
python nvidia_preprocessing.py -d path_of_wavs
За поиск мин и максимума F0 и энергии
python compute_statistics.py
Обновите следующее в hparams.py Min и Max of F0 и Energy
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


