AdaSpeech
1.0.0
Inoffizielle Pytorch -Implementierung von Adaspeech.
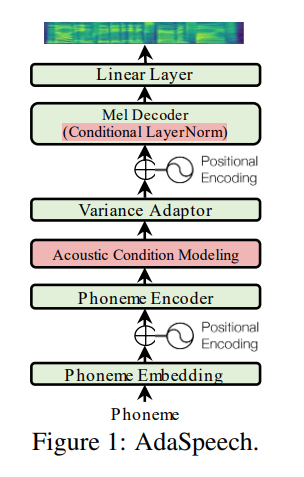
Utterance level encoder und die Norm der Phoneme level encoder (die Seele des Adaspeech -Papiers) verwenden, sondern eindeutig die adaptive Natur von Adaspeech einschränken, aber mein Fokus liegt auf der Verbesserung der akustischen Verallgemeinerung der Fastspeech 2 und nicht auf Anpassung. 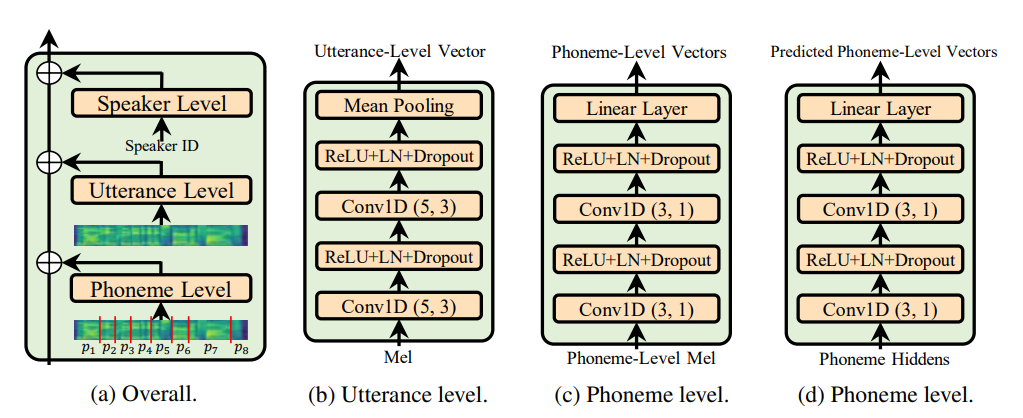
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
} Alle in Python 3.6.2 geschriebenen Code.
Vor der Installation von Pytorch überprüfen Sie bitte Ihre CUDA -Version, indem Sie den folgenden Befehl ausführen:
nvcc --version
pip install torch torchvision
In diesem Repo habe ich Pytorch 1.6.0 für torch.bucketize Funktion verwendet, die in früheren Pytorch -Versionen nicht vorhanden ist.
pip install -r requirements.txt
tensorboard version 1.14.0 separat mit unterstütztem tensorflow (1.14.0) filelists -Ordner enthält MFA -Datensatzdateien (Motreal Force Aligner), sodass Sie den Text für den LJSpeech -Datensatz nicht mit Audio (für die Extraktdauer) ausrichten müssen. Für einen anderen Datensatz folgen Sie den Anweisungen hier. Für andere vorverarbeitende Ausführungsbefehlsbefehl:
python nvidia_preprocessing.py -d path_of_wavs
Zum Auffinden der Min und Max von F0 und Energie
python compute_statistics.py
Aktualisieren Sie Folgendes in hparams.py von Min und Max von F0 und Energie
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


