AdaSpeech
1.0.0
การใช้งาน Pytorch อย่างไม่เป็นทางการของ Adaspeech
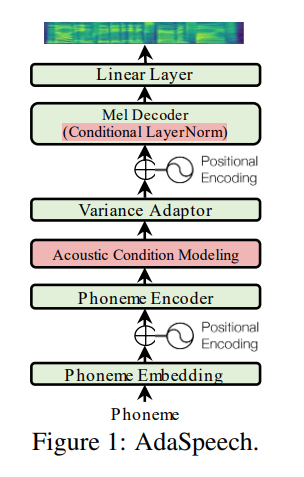
Utterance level encoder และ Phoneme level encoder ไม่ใช่บรรทัดฐานเลเยอร์เงื่อนไข (ซึ่งเป็นจิตวิญญาณของกระดาษ adaspeech) มัน จำกัด ลักษณะการปรับตัวของ adaspeech แต่โฟกัสของฉันคือการปรับปรุงการวางแนว Acoustic ทั่วไปมากกว่าการปรับตัว 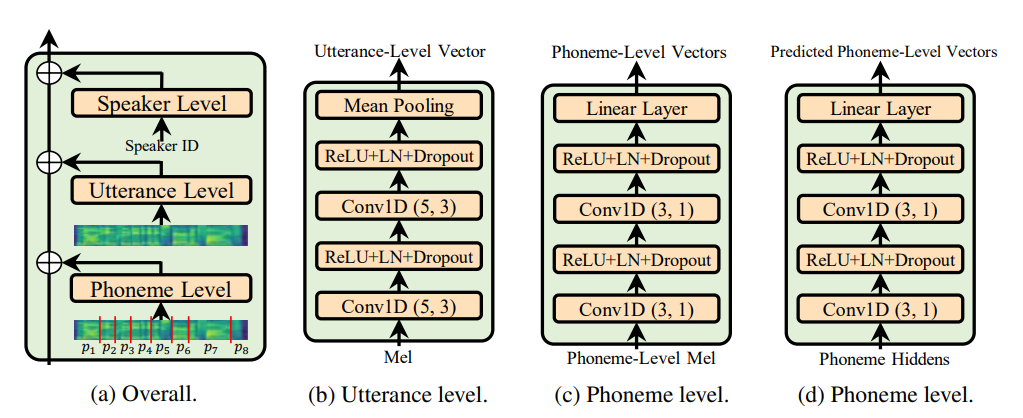
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
} รหัสทั้งหมดที่เขียนใน Python 3.6.2
ก่อนที่จะติดตั้ง pytorch โปรดตรวจสอบเวอร์ชัน cuda ของคุณโดยเรียกใช้คำสั่งต่อไปนี้:
nvcc --version
pip install torch torchvision
ใน repo นี้ฉันได้ใช้ pytorch 1.6.0 สำหรับคุณสมบัติ torch.bucketize ซึ่งไม่ได้อยู่ใน Pytorch เวอร์ชันก่อนหน้า
pip install -r requirements.txt
tensorboard version 1.14.0 Seperatly พร้อม tensorflow (1.14.0) โฟลเดอร์ filelists ประกอบด้วย MFA (Motreal Force Aligner) ไฟล์ชุดข้อมูล LJSpeech ที่ประมวลผลดังนั้นคุณไม่จำเป็นต้องจัดเรียงข้อความด้วยเสียง (สำหรับการแยกระยะเวลา) สำหรับชุดข้อมูล LJSpeech สำหรับชุดข้อมูลอื่น ๆ ตามคำสั่งที่นี่ สำหรับการประมวลผลก่อนการประมวลผลอื่น ๆ คำสั่งต่อไปนี้:
python nvidia_preprocessing.py -d path_of_wavs
สำหรับการค้นหาขั้นต่ำและสูงสุดของ F0 และพลังงาน
python compute_statistics.py
อัปเดตต่อไปนี้ใน hparams.py โดย min และ max ของ F0 และพลังงาน
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


