AdaSpeech
1.0.0
Implementação não oficial de pytorch do AdasPeech.
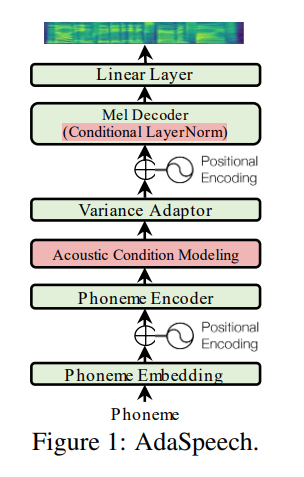
Utterance level encoder e Phoneme level encoder não a norma da camada de condição (que é a alma do papel de Adaspeech), ele restringe a natureza adaptativa da Adaspech, mas meu foco é melhorar a generalização acústica do FastSpeech 2 e não a adaptação. 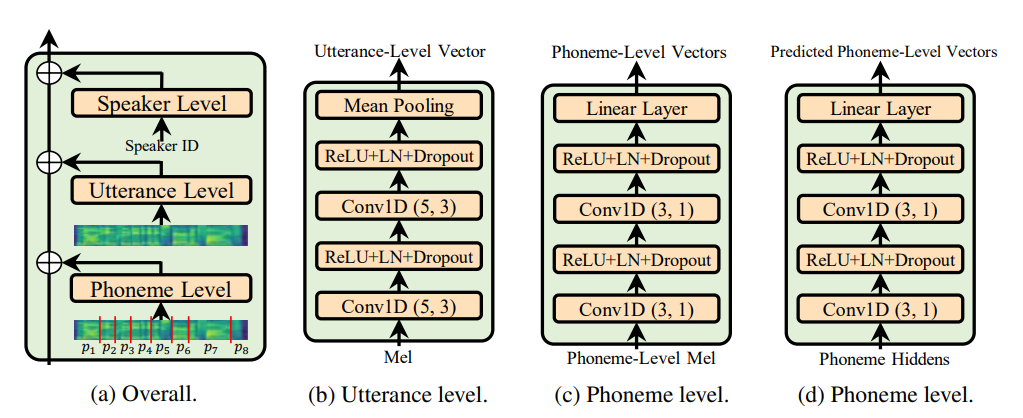
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
} Todo o código escrito no Python 3.6.2 .
Antes de instalar o Pytorch, verifique sua versão CUDA executando o seguinte comando:
nvcc --version
pip install torch torchvision
Neste repo, usei Pytorch 1.6.0 para o recurso torch.bucketize , que não está presente nas versões anteriores do Pytorch.
pip install -r requirements.txt
tensorboard version 1.14.0 Seperatly com tensorflow (1.14.0) A pasta filelists contém os arquivos de conjunto de dados LJSpeech MFA (Moteal Force Aligner), para que você não precise alinhar texto com áudio (para duração de extração) para o conjunto de dados LJSpeech. Para outro conjunto de dados, siga as instruções aqui. Para outros pré-processamento de execução seguindo o comando:
python nvidia_preprocessing.py -d path_of_wavs
Para encontrar o min e o máximo de f0 e energia
python compute_statistics.py
Atualize o seguinte em hparams.py por min e max de f0 e energia
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


