AdaSpeech
1.0.0
تنفيذ Pytorch غير رسمي من Adaspeech.
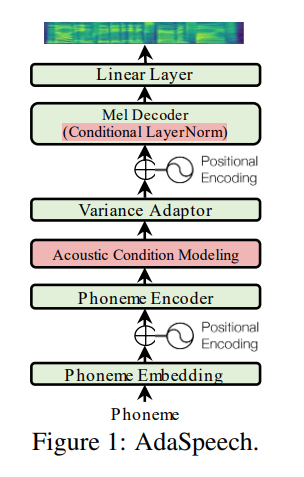
Utterance level encoder Phoneme level encoder ليس هناك قاعدة طبقة الحالة (التي هي روح ورق adaspeech) ، فهي تقيد الطبيعة التكيفية للأدوش ، لكن تركيزي هو تحسين التعميم الصوتي Fastspeech 2 بدلاً من التكيف. 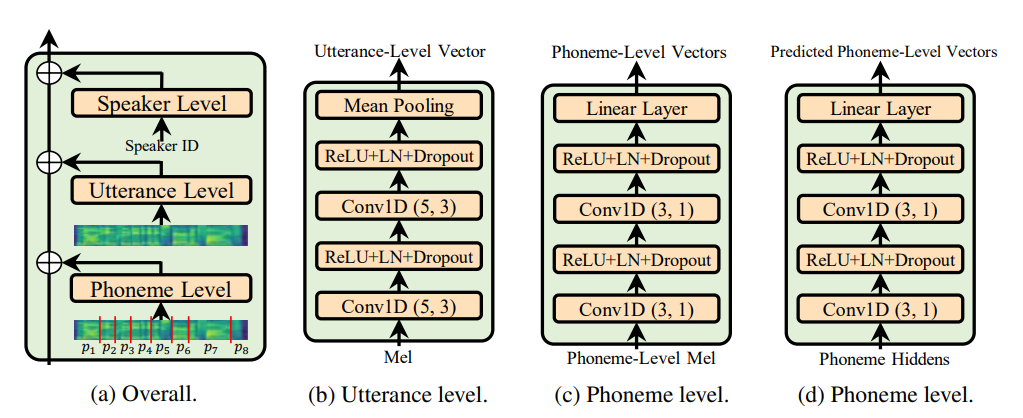
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
} جميع الكود المكتوب في Python 3.6.2 .
قبل تثبيت Pytorch ، يرجى التحقق من إصدار CUDA الخاص بك عن طريق تشغيل الأمر التالي:
nvcc --version
pip install torch torchvision
في هذا الريبو ، استخدمت Pytorch 1.6.0 لميزة torch.bucketize التي ليست موجودة في الإصدارات السابقة من Pytorch.
pip install -r requirements.txt
tensorboard version 1.14.0 seperatly مع tensorflow (1.14.0) يحتوي مجلد filelists على ملفات مجموعة بيانات MFA (MotReal Force) المعالجة LJSpeech بحيث لا تحتاج إلى محاذاة نص مع الصوت (لمدة الاستخراج) لمجموعة بيانات LJSPEEDE. لمجموعة البيانات الأخرى اتبع التعليمات هنا. للتشغيل المسبق للمعالجة المسبقة: الأمر التالي:
python nvidia_preprocessing.py -d path_of_wavs
للعثور على Min و Max من F0 والطاقة
python compute_statistics.py
قم بتحديث ما يلي في hparams.py بواسطة Min و Max من F0 والطاقة
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


