AdaSpeech
1.0.0
Implémentation non officielle pytorch d'Adaspeech.
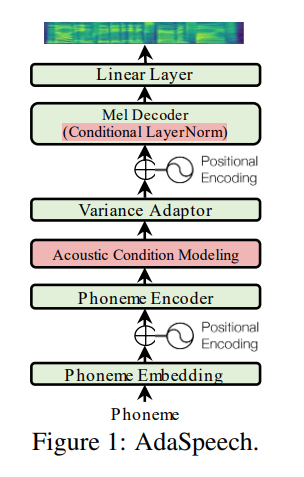
Utterance level encoder et Phoneme level encoder et non la norme de la couche de condition (qui est l'âme du papier adaspiche), il restreint définitivement la nature adaptative de l'adaseeche mais mon objectif est d'améliorer la généralisation acoustique de FastSpeech 2 plutôt que d'adaptation. 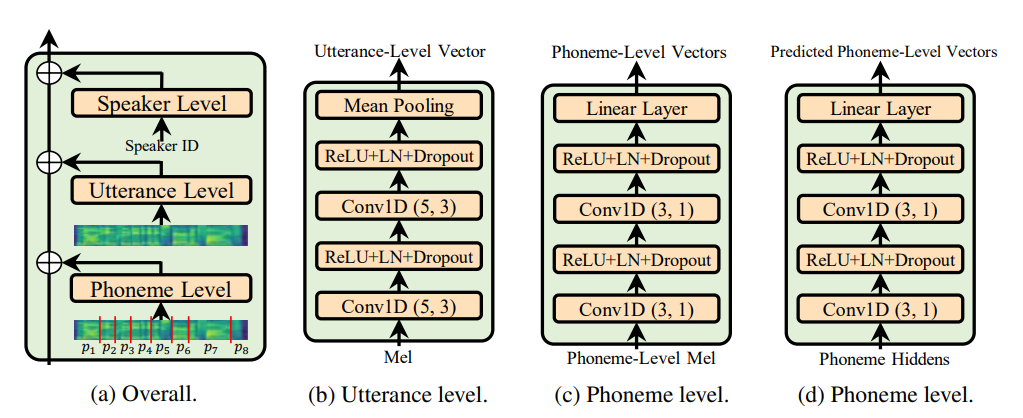
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
} Tout le code écrit en Python 3.6.2 .
Avant d'installer Pytorch, veuillez vérifier votre version CUDA en exécutant la commande suivante:
nvcc --version
pip install torch torchvision
Dans ce dépôt, j'ai utilisé Pytorch 1.6.0 pour la fonction torch.bucketize qui n'est pas présente dans les versions précédentes de Pytorch.
pip install -r requirements.txt
tensorboard version 1.14.0 séparément avec tensorflow (1.14.0) Le dossier filelists contient des fichiers de données LJSpeech traités MFA (MotReal Force Aligner), vous n'avez donc pas besoin d'aligner le texte avec l'audio (pour la durée d'extrait) pour l'ensemble de données LJSpeech. Pour un autre ensemble de données, suivez l'instruction ici. Pour d'autres prétraitements Exécuter la commande suivante:
python nvidia_preprocessing.py -d path_of_wavs
Pour trouver le min et le max de F0 et de l'énergie
python compute_statistics.py
Mettez à jour ce qui suit dans hparams.py par min et max de F0 et de l'énergie
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


