AdaSpeech
1.0.0
Adaspeechの非公式のPytorch実装。
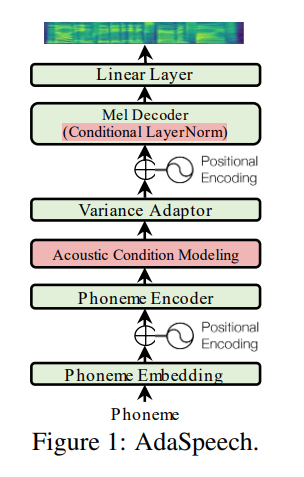
Utterance level encoderとPhoneme level encoderのみを使用します。 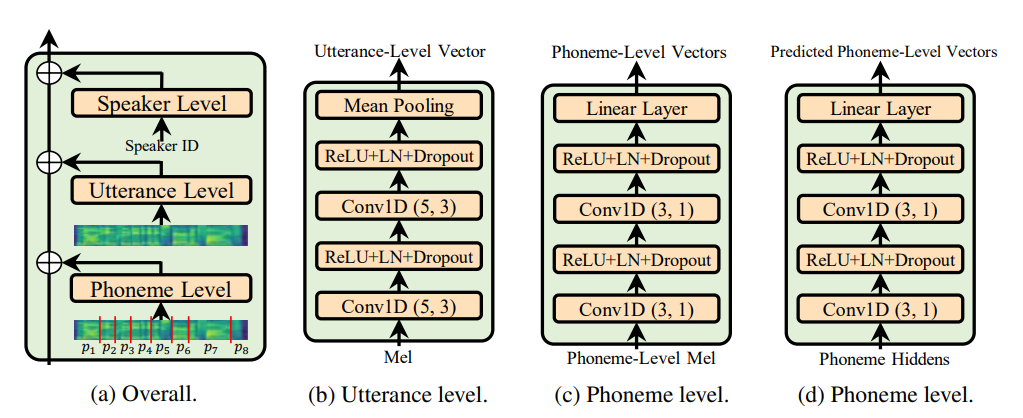
@misc { chen2021adaspeech ,
title = { AdaSpeech: Adaptive Text to Speech for Custom Voice } ,
author = { Mingjian Chen and Xu Tan and Bohan Li and Yanqing Liu and Tao Qin and Sheng Zhao and Tie-Yan Liu } ,
year = { 2021 } ,
eprint = { 2103.00993 } ,
archivePrefix = { arXiv } ,
primaryClass = { eess.AS }
} Python 3.6.2で記述されたすべてのコード。
Pytorchをインストールする前に、次のコマンドを実行してCUDAバージョンを確認してください:
nvcc --version
pip install torch torchvision
このレポでは、Pytorchの以前のバージョンには存在しないtorch.bucketize機能にPytorch 1.6.0を使用しました。
pip install -r requirements.txt
tensorboard version 1.14.0をサポートしたtensorflow (1.14.0)をインストールする filelistsフォルダーには、MFA(Motreal Force Aligner)処理されたLJSpeech Datasetファイルが含まれるため、LJSpeech Datasetのオーディオ(抽出期間用)にテキストを合わせる必要はありません。他のデータセットについては、ここで命令をフォローしてください。次のコマンドを次のように処理する他の処理実行の場合:
python nvidia_preprocessing.py -d path_of_wavs
F0とエネルギーの最小と最大を見つけるために
python compute_statistics.py
hparams.pyで以下を更新します。
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"


