PAFTS
v1.0.0
該庫可以簡單地將音頻文件處理為適用於TTS培訓數據的格式,並簡單地執行。 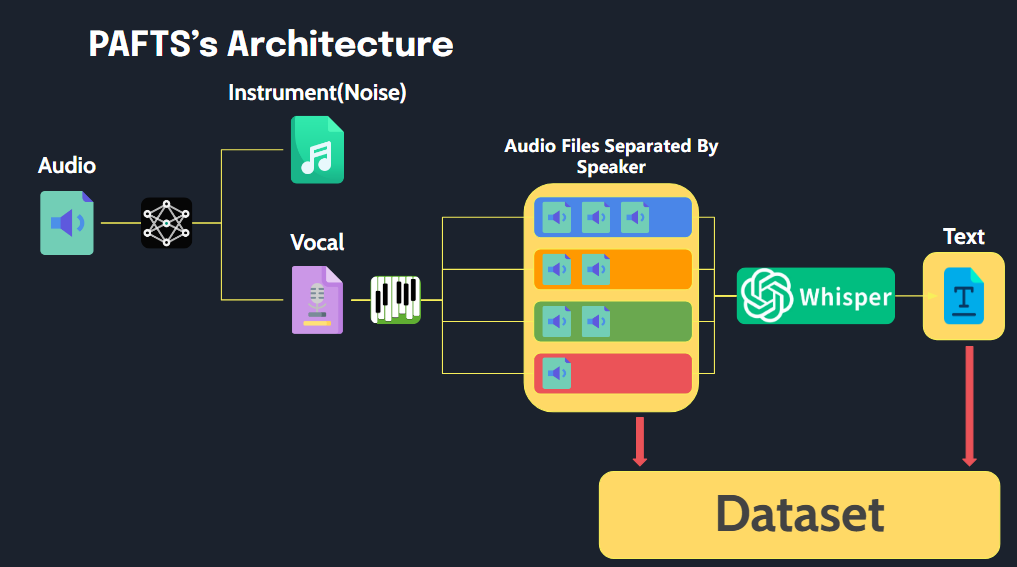
Pafts具有三個功能。
# before run()
path
├── 1_001.wav # have mr or noise
├── 1_002.wav
├── 1_003.wav
├── 1_004.wav
└── abc.wav
# after run()
path
├── SPEAKER_00
│ ├── SPEAKER_00_1.wav # removed mr and noise
│ ├── SPEAKER_00_2.wav
│ └── SPEAKER_00_3.wav
├── SPEAKER_01
│ ├── SPEAKER_01_1.wav
│ └── SPEAKER_01_2.wav
├── SPEAKER_02
│ ├── SPEAKER_02_1.wav
│ └── SPEAKER_02_2.wav
└── audio.json
# audio.json
{
'SPEAKER_00_1.wav' : "I have a note.",
'SPEAKER_00_2.wav' : "I want to eat chicken.",
'SPEAKER_00_3.wav' : "...",
'SPEAKER_01_1.wav' : "...",
'SPEAKER_01_2.wav' : "...",
}
該庫是使用Python 3.10開發的,我們建議使用Python版本3.8至3.10進行兼容。
雖然庫與Linux和Windows都兼容,但所有測試均在Windows上進行。對於在Linux上運行時遇到的任何問題或錯誤,請隨時打開問題。
在運行庫之前,請確保安裝以下內容:
我們強烈建議使用GPU優化性能。對於Pytorch安裝,請按照以下命令確保與GPU的兼容性
# Example for installing PyTorch with CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
FFMPEG是本庫中音頻處理任務所必需的。請確保從系統的路徑上安裝並可以訪問。安裝FFMPEG:
從FFMPEG的官方網站下載最新的FFMPEG版本,然後將BIN文件夾添加到您的系統路徑中。
使用以下命令安裝FFMPEG:
sudo apt update
sudo apt install ffmpeg
安裝後,您可以通過運行驗證
ffmpeg -version
要啟用診斷功能,請完成以下步驟
pyannote/segmentation-3.0用戶條件pyannote/speaker-diarization-3.1用戶條件hf.co/settings/tokens上創建訪問令牌。 from pafts.pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE"
)
完成上面的設置步驟後,您可以通過運行來安裝此庫
pip install pafts
from pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE" # if you use diarization
)
# Separator
p.separator()
# Diarization
p.diarization()
# STT
p.STT(model_size='small')
# One-Click Process
p.run()
PAFTS的代碼是MIT許可的


