PAFTS
v1.0.0
تتيح هذه المكتبة معالجة الملفات الصوتية السهلة لتنسيق مناسب لبيانات التدريب TTS مع تنفيذ بسيط. 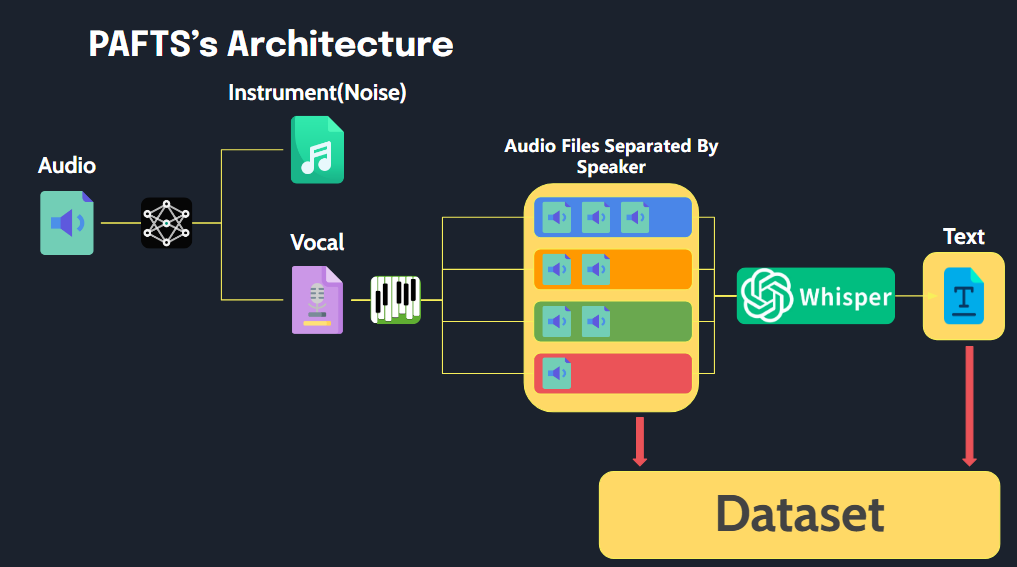
Pafts لها ثلاث ميزات.
# before run()
path
├── 1_001.wav # have mr or noise
├── 1_002.wav
├── 1_003.wav
├── 1_004.wav
└── abc.wav
# after run()
path
├── SPEAKER_00
│ ├── SPEAKER_00_1.wav # removed mr and noise
│ ├── SPEAKER_00_2.wav
│ └── SPEAKER_00_3.wav
├── SPEAKER_01
│ ├── SPEAKER_01_1.wav
│ └── SPEAKER_01_2.wav
├── SPEAKER_02
│ ├── SPEAKER_02_1.wav
│ └── SPEAKER_02_2.wav
└── audio.json
# audio.json
{
'SPEAKER_00_1.wav' : "I have a note.",
'SPEAKER_00_2.wav' : "I want to eat chicken.",
'SPEAKER_00_3.wav' : "...",
'SPEAKER_01_1.wav' : "...",
'SPEAKER_01_2.wav' : "...",
}
تم تطوير هذه المكتبة باستخدام Python 3.10 ، ونوصي باستخدام إصدارات Python من 3.8 إلى 3.10 للتوافق.
في حين أن المكتبة متوافقة مع كل من Linux و Windows ، تم إجراء جميع الاختبارات على Windows. لأي مشكلات أو أخطاء تمت مواجهتها أثناء التشغيل على Linux ، لا تتردد في فتح مشكلة.
قبل تشغيل المكتبة ، يرجى التأكد من تثبيت ما يلي:
نوصي بشدة باستخدام وحدة معالجة الرسومات لتحسين الأداء. لتثبيت Pytorch ، يرجى اتباع الأوامر أدناه لضمان التوافق مع GPU الخاص بك
# Example for installing PyTorch with CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
FFMPEG مطلوب لمهام معالجة الصوت داخل هذه المكتبة. يرجى التأكد من تثبيته ويمكن الوصول إليه من مسار نظامك. لتثبيت FFMPEG:
قم بتنزيل أحدث إصدار FFMPEG من موقع FFMPEG الرسمي ، وأضف مجلد BIN إلى مسار نظامك.
استخدم الأمر التالي لتثبيت FFMPEG:
sudo apt update
sudo apt install ffmpeg
بعد التثبيت ، يمكنك التحقق من خلال التشغيل
ffmpeg -version
لتمكين وظائف التهوية ، يرجى إكمال الخطوات التالية
pyannote/segmentation-3.0pyannote/speaker-diarization-3.1hf.co/settings/tokens . from pafts.pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE"
)
بعد الانتهاء من خطوات الإعداد أعلاه ، يمكنك تثبيت هذه المكتبة عن طريق التشغيل
pip install pafts
from pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE" # if you use diarization
)
# Separator
p.separator()
# Diarization
p.diarization()
# STT
p.STT(model_size='small')
# One-Click Process
p.run()
مدونة بافتات مرخصة معهد ماساتشوستس للتكنولوجيا


