PAFTS
v1.0.0
Diese Bibliothek ermöglicht eine einfache Verarbeitung von Audiodateien in einem Format, das für TTS -Schulungsdaten mit einer einfachen Ausführung geeignet ist.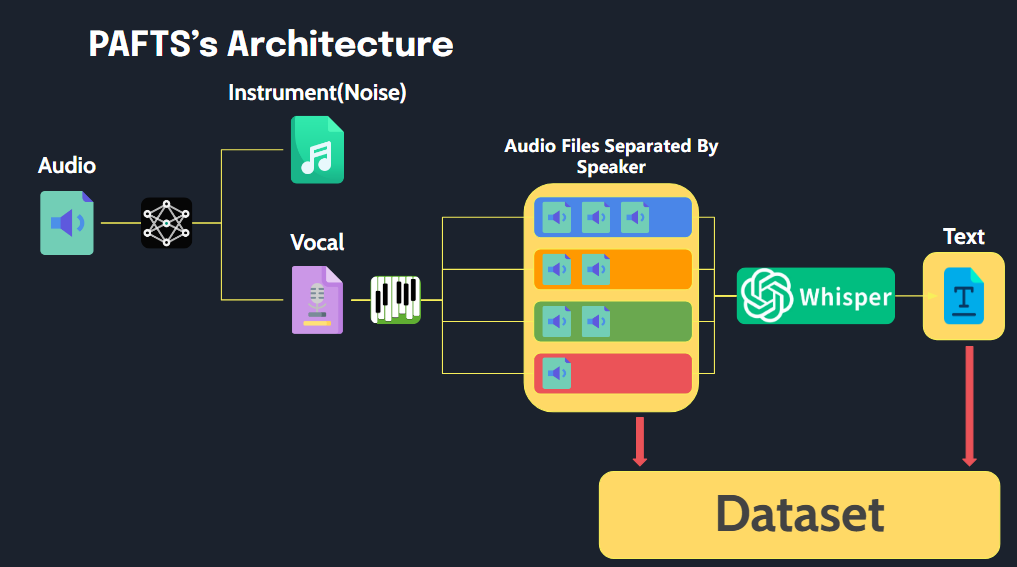
Pafts haben drei Funktionen.
# before run()
path
├── 1_001.wav # have mr or noise
├── 1_002.wav
├── 1_003.wav
├── 1_004.wav
└── abc.wav
# after run()
path
├── SPEAKER_00
│ ├── SPEAKER_00_1.wav # removed mr and noise
│ ├── SPEAKER_00_2.wav
│ └── SPEAKER_00_3.wav
├── SPEAKER_01
│ ├── SPEAKER_01_1.wav
│ └── SPEAKER_01_2.wav
├── SPEAKER_02
│ ├── SPEAKER_02_1.wav
│ └── SPEAKER_02_2.wav
└── audio.json
# audio.json
{
'SPEAKER_00_1.wav' : "I have a note.",
'SPEAKER_00_2.wav' : "I want to eat chicken.",
'SPEAKER_00_3.wav' : "...",
'SPEAKER_01_1.wav' : "...",
'SPEAKER_01_2.wav' : "...",
}
Diese Bibliothek wurde unter Verwendung von Python 3.10 entwickelt, und wir empfehlen, Python -Versionen 3.8 bis 3.10 für die Kompatibilität zu verwenden.
Während die Bibliothek sowohl mit Linux als auch mit Windows kompatibel ist, wurden alle Tests unter Windows durchgeführt. Bei Problemen oder Fehlern, die beim Laufen auf Linux auftreten, können Sie ein Problem frei eröffnen.
Stellen Sie vor dem Ausführen der Bibliothek sicher, dass die folgenden Installationen installiert sind:
Wir empfehlen dringend, eine GPU zu verwenden, um die Leistung zu optimieren. Für die Installation von Pytorch folgen Sie bitte den folgenden Befehlen, um die Kompatibilität mit Ihrer GPU sicherzustellen
# Example for installing PyTorch with CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
FFMPEG ist für Audioverarbeitungsaufgaben in dieser Bibliothek erforderlich. Bitte stellen Sie sicher, dass es vom Pfad Ihres Systems installiert und zugänglich ist. So installieren Sie FFMPEG:
Laden Sie die neueste FFMPEG -Version von der offiziellen Website von FFMPEG herunter und fügen Sie den Bin -Ordner dem Pfad Ihres Systems hinzu.
Verwenden Sie den folgenden Befehl, um FFMPEG zu installieren:
sudo apt update
sudo apt install ffmpeg
Nach der Installation können Sie durch Ausführen überprüfen
ffmpeg -version
Um Diarisierungsfunktionen zu ermöglichen, führen Sie bitte die folgenden Schritte aus
pyannote/segmentation-3.0 Benutzerbedingungenpyannote/speaker-diarization-3.1 Benutzerbedingungenhf.co/settings/tokens . from pafts.pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE"
)
Nachdem Sie die obigen Einrichtungsschritte ausgeschlossen haben, können Sie diese Bibliothek durch Ausführen installieren
pip install pafts
from pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE" # if you use diarization
)
# Separator
p.separator()
# Diarization
p.diarization()
# STT
p.STT(model_size='small')
# One-Click Process
p.run()
Der Code von Pafts ist MIT-lizenziert


