PAFTS
v1.0.0
ไลบรารีนี้ช่วยให้การประมวลผลไฟล์เสียงง่ายขึ้นในรูปแบบที่เหมาะสำหรับข้อมูลการฝึกอบรม TTS ด้วยการดำเนินการอย่างง่าย 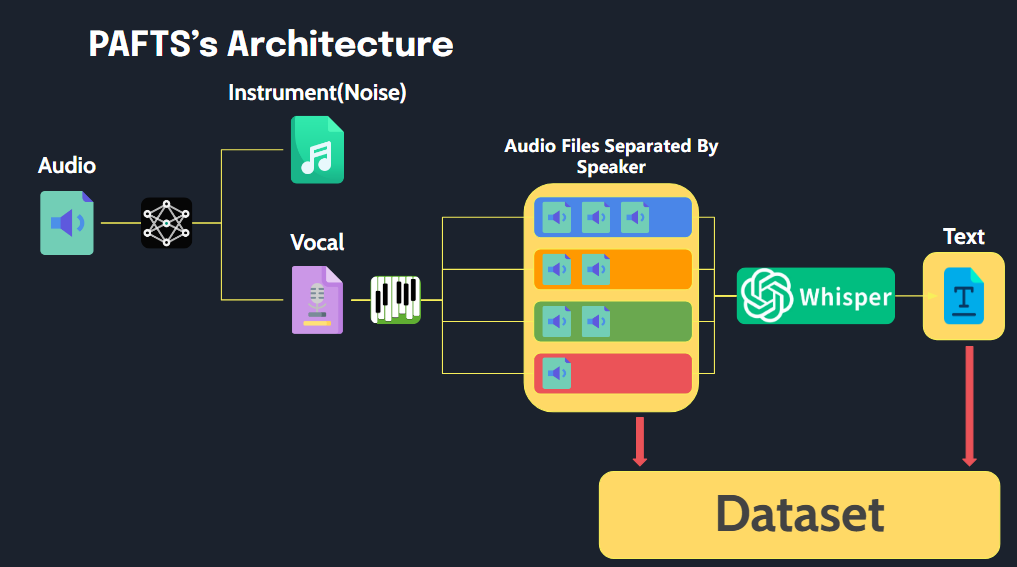
Pafts มีสามคุณสมบัติ
# before run()
path
├── 1_001.wav # have mr or noise
├── 1_002.wav
├── 1_003.wav
├── 1_004.wav
└── abc.wav
# after run()
path
├── SPEAKER_00
│ ├── SPEAKER_00_1.wav # removed mr and noise
│ ├── SPEAKER_00_2.wav
│ └── SPEAKER_00_3.wav
├── SPEAKER_01
│ ├── SPEAKER_01_1.wav
│ └── SPEAKER_01_2.wav
├── SPEAKER_02
│ ├── SPEAKER_02_1.wav
│ └── SPEAKER_02_2.wav
└── audio.json
# audio.json
{
'SPEAKER_00_1.wav' : "I have a note.",
'SPEAKER_00_2.wav' : "I want to eat chicken.",
'SPEAKER_00_3.wav' : "...",
'SPEAKER_01_1.wav' : "...",
'SPEAKER_01_2.wav' : "...",
}
ไลบรารีนี้ได้รับการพัฒนาโดยใช้ Python 3.10 และเราขอแนะนำให้ใช้ Python Version 3.8 ถึง 3.10 สำหรับความเข้ากันได้
ในขณะที่ห้องสมุดเข้ากันได้กับทั้ง Linux และ Windows การทดสอบทั้งหมดได้ดำเนินการบน Windows สำหรับปัญหาหรือข้อผิดพลาดใด ๆ ที่พบขณะทำงานบน Linux โปรดเปิดปัญหา
ก่อนที่จะเรียกใช้ห้องสมุดโปรดตรวจสอบให้แน่ใจว่ามีการติดตั้งต่อไปนี้:
เราขอแนะนำให้ใช้ GPU เพื่อเพิ่มประสิทธิภาพประสิทธิภาพ สำหรับการติดตั้ง pytorch โปรดทำตามคำสั่งด้านล่างเพื่อให้แน่ใจว่าเข้ากันได้กับ GPU ของคุณ
# Example for installing PyTorch with CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
FFMPEG เป็นสิ่งจำเป็นสำหรับงานประมวลผลเสียงภายในไลบรารีนี้ โปรดตรวจสอบให้แน่ใจว่าได้รับการติดตั้งและเข้าถึงได้จากเส้นทางของระบบของคุณ ในการติดตั้ง ffmpeg:
ดาวน์โหลดรุ่น FFMPEG ล่าสุดจากเว็บไซต์ทางการของ FFMPEG และเพิ่มโฟลเดอร์ bin ลงในเส้นทางของระบบของคุณ
ใช้คำสั่งต่อไปนี้เพื่อติดตั้ง ffmpeg:
sudo apt update
sudo apt install ffmpeg
หลังจากการติดตั้งคุณสามารถตรวจสอบได้โดยการรัน
ffmpeg -version
หากต้องการเปิดใช้งานฟังก์ชั่น diarization โปรดทำตามขั้นตอนต่อไปนี้
pyannote/segmentation-3.0pyannote/speaker-diarization-3.1hf.co/settings/tokens from pafts.pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE"
)
หลังจากเสร็จสิ้นขั้นตอนการตั้งค่าด้านบนคุณสามารถติดตั้งไลบรารีนี้ได้โดยเรียกใช้
pip install pafts
from pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE" # if you use diarization
)
# Separator
p.separator()
# Diarization
p.diarization()
# STT
p.STT(model_size='small')
# One-Click Process
p.run()
รหัสของ pafts ได้รับใบอนุญาต mit


