PAFTS
v1.0.0
Perpustakaan ini memungkinkan pemrosesan file audio yang mudah menjadi format yang cocok untuk data pelatihan TTS dengan eksekusi sederhana. 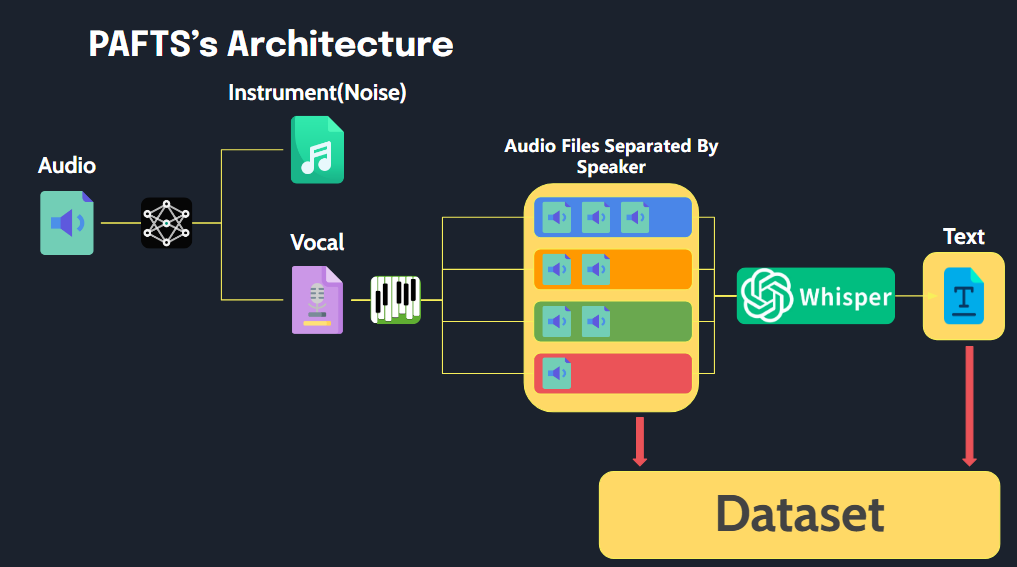
Paft memiliki tiga fitur.
# before run()
path
├── 1_001.wav # have mr or noise
├── 1_002.wav
├── 1_003.wav
├── 1_004.wav
└── abc.wav
# after run()
path
├── SPEAKER_00
│ ├── SPEAKER_00_1.wav # removed mr and noise
│ ├── SPEAKER_00_2.wav
│ └── SPEAKER_00_3.wav
├── SPEAKER_01
│ ├── SPEAKER_01_1.wav
│ └── SPEAKER_01_2.wav
├── SPEAKER_02
│ ├── SPEAKER_02_1.wav
│ └── SPEAKER_02_2.wav
└── audio.json
# audio.json
{
'SPEAKER_00_1.wav' : "I have a note.",
'SPEAKER_00_2.wav' : "I want to eat chicken.",
'SPEAKER_00_3.wav' : "...",
'SPEAKER_01_1.wav' : "...",
'SPEAKER_01_2.wav' : "...",
}
Perpustakaan ini dikembangkan menggunakan Python 3.10, dan kami sarankan menggunakan Python Versions 3.8 hingga 3.10 untuk kompatibilitas.
Sementara pustaka kompatibel dengan Linux dan Windows, semua pengujian dilakukan pada Windows. Untuk masalah atau kesalahan yang dihadapi saat menjalankan di Linux, jangan ragu untuk membuka masalah.
Sebelum menjalankan perpustakaan, pastikan yang berikut ini diinstal:
Kami sangat merekomendasikan menggunakan GPU untuk mengoptimalkan kinerja. Untuk instalasi Pytorch, silakan ikuti perintah di bawah ini untuk memastikan kompatibilitas dengan GPU Anda
# Example for installing PyTorch with CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
FFMPEG diperlukan untuk tugas pemrosesan audio dalam perpustakaan ini. Harap pastikan itu diinstal dan dapat diakses dari jalur sistem Anda. Untuk menginstal ffmpeg:
Unduh rilis FFMPEG terbaru dari situs web resmi FFMPEG, dan tambahkan folder bin ke jalur sistem Anda.
Gunakan perintah berikut untuk menginstal FFMPEG:
sudo apt update
sudo apt install ffmpeg
Setelah instalasi, Anda dapat memverifikasi dengan menjalankan
ffmpeg -version
Untuk mengaktifkan fungsionalitas Diarization, harap selesaikan langkah -langkah berikut
pyannote/segmentation-3.0pyannote/speaker-diarization-3.1 Kondisi Penggunahf.co/settings/tokens . from pafts.pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE"
)
Setelah menyelesaikan langkah pengaturan di atas, Anda dapat menginstal perpustakaan ini dengan menjalankan
pip install pafts
from pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE" # if you use diarization
)
# Separator
p.separator()
# Diarization
p.diarization()
# STT
p.STT(model_size='small')
# One-Click Process
p.run()
Kode Pafts dilisensikan MIT


