PAFTS
v1.0.0
Cette bibliothèque permet un traitement facile des fichiers audio dans un format adapté aux données de formation TTS avec une exécution simple. 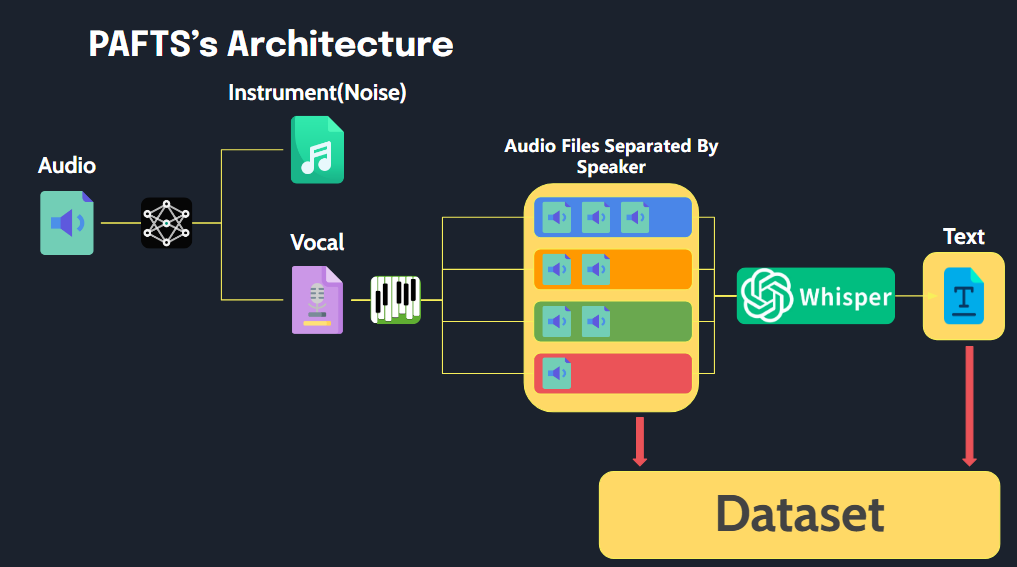
Les Pafts ont trois fonctionnalités.
# before run()
path
├── 1_001.wav # have mr or noise
├── 1_002.wav
├── 1_003.wav
├── 1_004.wav
└── abc.wav
# after run()
path
├── SPEAKER_00
│ ├── SPEAKER_00_1.wav # removed mr and noise
│ ├── SPEAKER_00_2.wav
│ └── SPEAKER_00_3.wav
├── SPEAKER_01
│ ├── SPEAKER_01_1.wav
│ └── SPEAKER_01_2.wav
├── SPEAKER_02
│ ├── SPEAKER_02_1.wav
│ └── SPEAKER_02_2.wav
└── audio.json
# audio.json
{
'SPEAKER_00_1.wav' : "I have a note.",
'SPEAKER_00_2.wav' : "I want to eat chicken.",
'SPEAKER_00_3.wav' : "...",
'SPEAKER_01_1.wav' : "...",
'SPEAKER_01_2.wav' : "...",
}
Cette bibliothèque a été développée à l'aide de Python 3.10, et nous vous recommandons d'utiliser les versions Python 3.8 à 3.10 pour la compatibilité.
Bien que la bibliothèque soit compatible avec Linux et Windows, tous les tests ont été effectués sur Windows. Pour tout problème ou erreur rencontré lors de l'exécution sur Linux, n'hésitez pas à ouvrir un problème.
Avant d'exécuter la bibliothèque, veuillez vous assurer que ce qui suit est installé:
Nous vous recommandons fortement d'utiliser un GPU pour optimiser les performances. Pour l'installation de Pytorch, veuillez suivre les commandes ci-dessous pour assurer la compatibilité avec votre GPU
# Example for installing PyTorch with CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
FFMPEG est requis pour les tâches de traitement audio dans cette bibliothèque. Veuillez vous assurer qu'il est installé et accessible à partir du chemin de votre système. Pour installer ffmpeg:
Téléchargez la dernière version FFMPEG sur le site officiel de FFMPEG et ajoutez le dossier BIN au chemin de votre système.
Utilisez la commande suivante pour installer ffmpeg:
sudo apt update
sudo apt install ffmpeg
Après l'installation, vous pouvez vérifier en exécutant
ffmpeg -version
Pour permettre la fonctionnalité de diarisation, veuillez suivre les étapes suivantes
pyannote/segmentation-3.0pyannote/speaker-diarization-3.1 Conditions utilisateurhf.co/settings/tokens . from pafts.pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE"
)
Après avoir terminé les étapes de configuration ci-dessus, vous pouvez installer cette bibliothèque en exécutant
pip install pafts
from pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE" # if you use diarization
)
# Separator
p.separator()
# Diarization
p.diarization()
# STT
p.STT(model_size='small')
# One-Click Process
p.run()
Le code de PAFTS est licencié du MIT


