PAFTS
v1.0.0
Esta biblioteca permite un fácil procesamiento de archivos de audio en un formato adecuado para datos de capacitación TTS con una ejecución simple. 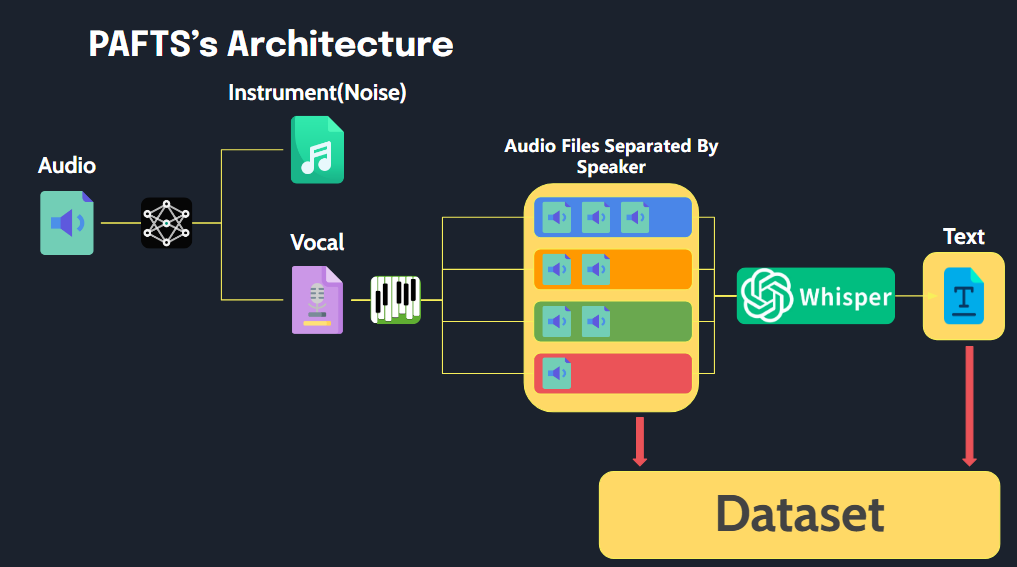
Pafts tiene tres características.
# before run()
path
├── 1_001.wav # have mr or noise
├── 1_002.wav
├── 1_003.wav
├── 1_004.wav
└── abc.wav
# after run()
path
├── SPEAKER_00
│ ├── SPEAKER_00_1.wav # removed mr and noise
│ ├── SPEAKER_00_2.wav
│ └── SPEAKER_00_3.wav
├── SPEAKER_01
│ ├── SPEAKER_01_1.wav
│ └── SPEAKER_01_2.wav
├── SPEAKER_02
│ ├── SPEAKER_02_1.wav
│ └── SPEAKER_02_2.wav
└── audio.json
# audio.json
{
'SPEAKER_00_1.wav' : "I have a note.",
'SPEAKER_00_2.wav' : "I want to eat chicken.",
'SPEAKER_00_3.wav' : "...",
'SPEAKER_01_1.wav' : "...",
'SPEAKER_01_2.wav' : "...",
}
Esta biblioteca se desarrolló con Python 3.10, y recomendamos usar las versiones de Python 3.8 a 3.10 para compatibilidad.
Si bien la biblioteca es compatible con Linux y Windows, todas las pruebas se realizaron en Windows. Para cualquier problema o error encontrado mientras se ejecuta en Linux, no dude en abrir un problema.
Antes de ejecutar la biblioteca, asegúrese de que se instale lo siguiente:
Recomendamos encarecidamente el uso de una GPU para optimizar el rendimiento. Para la instalación de Pytorch, siga los comandos a continuación para garantizar la compatibilidad con su GPU
# Example for installing PyTorch with CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Se requiere FFMPEG para tareas de procesamiento de audio dentro de esta biblioteca. Asegúrese de que esté instalado y accesible desde la ruta de su sistema. Para instalar ffmpeg:
Descargue la última versión de FFMPEG desde el sitio web oficial de FFMPEG y agregue la carpeta bin a la ruta de su sistema.
Use el siguiente comando para instalar ffmpeg:
sudo apt update
sudo apt install ffmpeg
Después de la instalación, puede verificar ejecutando
ffmpeg -version
Para habilitar la funcionalidad de diarización, complete los siguientes pasos
pyannote/segmentation-3.0 Condiciones del usuariopyannote/speaker-diarization-3.1 condiciones del usuariohf.co/settings/tokens . from pafts.pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE"
)
Después de completar los pasos de configuración anteriores, puede instalar esta biblioteca ejecutando
pip install pafts
from pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE" # if you use diarization
)
# Separator
p.separator()
# Diarization
p.diarization()
# STT
p.STT(model_size='small')
# One-Click Process
p.run()
El código de Pafts tiene licencia de MIT


