PAFTS
v1.0.0
Esta biblioteca permite fácil processamento de arquivos de áudio em um formato adequado para dados de treinamento TTS com uma execução simples.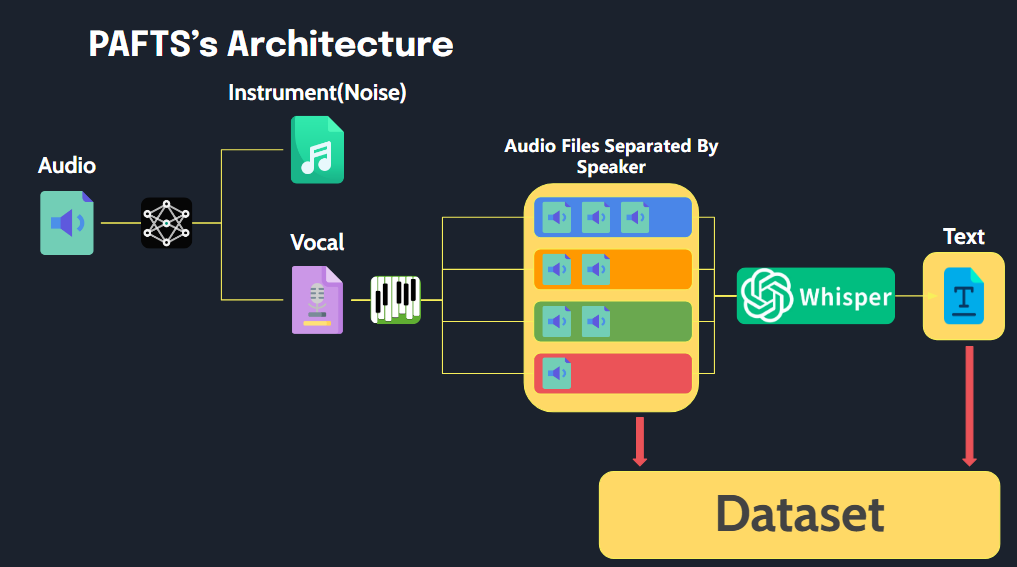
Os PAFTS têm três recursos.
# before run()
path
├── 1_001.wav # have mr or noise
├── 1_002.wav
├── 1_003.wav
├── 1_004.wav
└── abc.wav
# after run()
path
├── SPEAKER_00
│ ├── SPEAKER_00_1.wav # removed mr and noise
│ ├── SPEAKER_00_2.wav
│ └── SPEAKER_00_3.wav
├── SPEAKER_01
│ ├── SPEAKER_01_1.wav
│ └── SPEAKER_01_2.wav
├── SPEAKER_02
│ ├── SPEAKER_02_1.wav
│ └── SPEAKER_02_2.wav
└── audio.json
# audio.json
{
'SPEAKER_00_1.wav' : "I have a note.",
'SPEAKER_00_2.wav' : "I want to eat chicken.",
'SPEAKER_00_3.wav' : "...",
'SPEAKER_01_1.wav' : "...",
'SPEAKER_01_2.wav' : "...",
}
Esta biblioteca foi desenvolvida usando o Python 3.10 e recomendamos o uso de versões Python 3.8 a 3.10 para compatibilidade.
Enquanto a biblioteca é compatível com o Linux e o Windows, todos os testes foram realizados no Windows. Para quaisquer problemas ou erros encontrados durante a execução no Linux, sinta -se à vontade para abrir um problema.
Antes de executar a biblioteca, verifique se o seguinte está instalado:
É altamente recomendável usar uma GPU para otimizar o desempenho. Para a instalação do Pytorch, siga os comandos abaixo para garantir a compatibilidade com sua GPU
# Example for installing PyTorch with CUDA 11.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
O FFMPEG é necessário para tarefas de processamento de áudio nessa biblioteca. Verifique se está instalado e acessível a partir do caminho do seu sistema. Para instalar o ffmpeg:
Faça o download da versão mais recente do FFMPEG no site oficial do FFMPEG e adicione a pasta BIN ao caminho do seu sistema.
Use o seguinte comando para instalar o ffmpeg:
sudo apt update
sudo apt install ffmpeg
Após a instalação, você pode verificar executando
ffmpeg -version
Para ativar a funcionalidade de diarização, preencha as seguintes etapas
pyannote/segmentation-3.0 Condições do usuáriopyannote/speaker-diarization-3.1 Condições do usuáriohf.co/settings/tokens . from pafts.pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE"
)
Depois de concluir as etapas de configuração acima, você pode instalar esta biblioteca executando
pip install pafts
from pafts import PAFTS
p = PAFTS(
path = 'your_audio_directory_path',
output_path = 'output_path',
hf_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE" # if you use diarization
)
# Separator
p.separator()
# Diarization
p.diarization()
# STT
p.STT(model_size='small')
# One-Click Process
p.run()
O código de PAFTS é licenciado por MIT


