簡介
- 本項目的目的是拓展Bert-VITS2的使用邊界,比如TTS同步產生臉部表情數據。
- 效果參見
- Demo 嗶哩嗶哩Youtube
- TTS with Audio2PhotoReal --> MetaHuman
- 從歌聲生成表情測試;與Azure TTS說話時的表情對比
- TTS生成表情初版,與MotionGPT擬合
擴展到CosyVoice
擴展到GPT-SoVITS
- GPT-SoVITS 表情測試
- 直接在GPT-SoVITS上重新訓練,實測結果比較糟糕
- 暫時使用的方法是從Bert-VITS2-ext裡直接把後驗部分以及表情生成部分模型複製到GPT-SoVITS裡測試。
- 這會導致一次重複的計算,以及更多的預測變差
TTS
TTS代碼源自Bert-VITS2 v2.3 Final Release [ Dec 20, 2023]
- https://github.com/fishaudio/Bert-VITS2/commit/7ebc1aa28a055608f7e31da93928cf295fdffeba
測試下來,個人感覺純中文素材的訓練效果2.1-2.3版本略微不如1.0,純中文需求可以考慮降低版本或混合使用。
TTS本身的訓練方法見原文(每個版本都有所不同)
- 1.0版本推薦參考https://github.com/YYuX-1145/Bert-VITS2-Integration-package
TTS同步輸出表情
思路
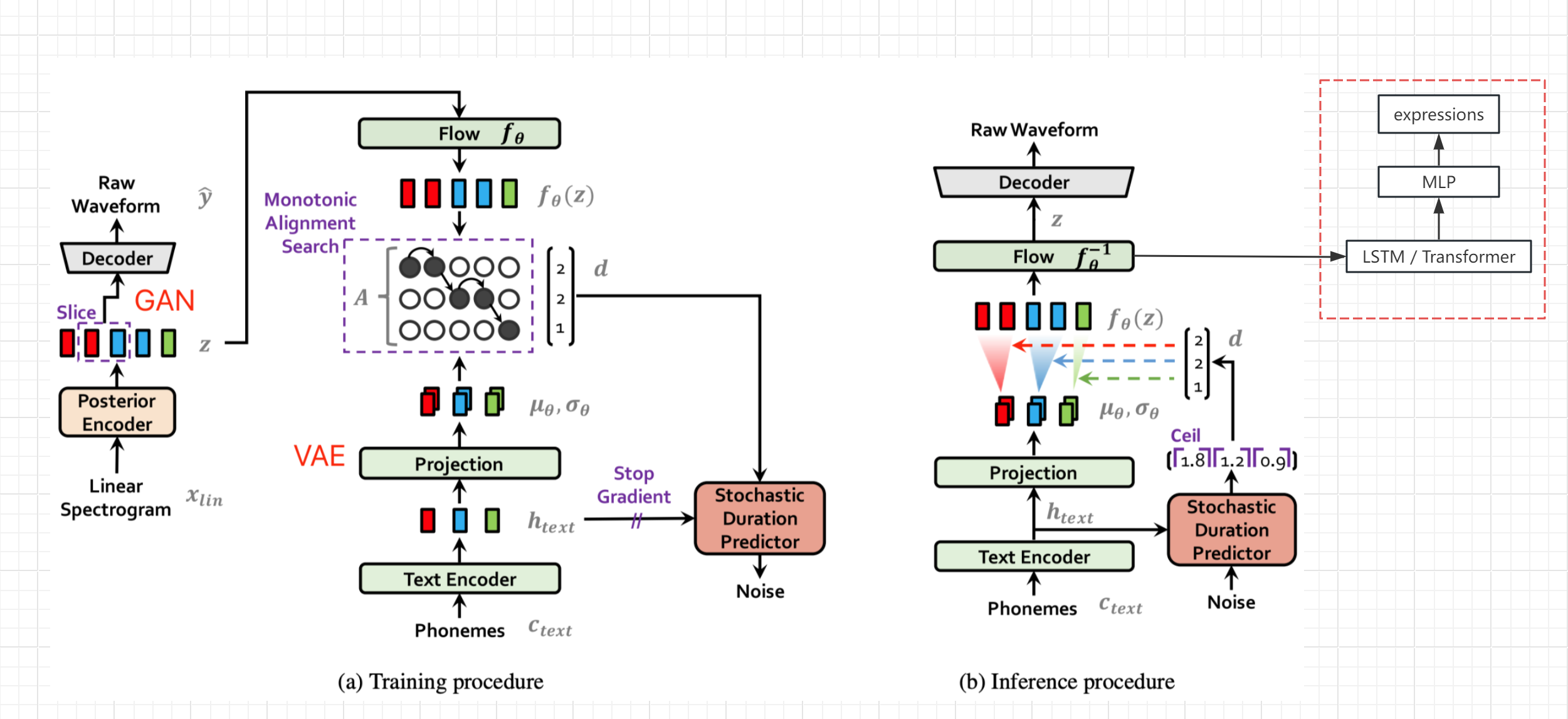
- 參考VITS論文的網絡結構圖(非bert-vits2,但大體結構是一樣的),獲取文本編碼及變換後、解碼前的隱變量z,從旁路輸出表情值(Live Link Face數值)
- 凍結原網絡的參數,單獨增加一路LSTM和MLP處理,完成z到表情的seq2seq生成與映射
- 當然如果有高質量的表情數據,也可以把表情也加入原始TTS網絡訓練,應該能提高音頻質量
數據採集
- 設置Live Link Face 的Targets 為本機IP,端口默認11111
- 同步採集語音和對應的Live Link輸出的表情值,分別存入到records文件夾
- 執行一下腳本採集,每次20秒
- 音頻默認為44100 Hz
- 音頻、表情的採集可能有偏移
- 可對比驗證集的損失找到同一數據源的最佳偏移位置
python ./motion/record.py
查看數據是否正常
測試數據
- 將錄下的bs數據通過live link發給UE中的MetaHuman,同步播放語音,檢查是否匹配
python ./motion/tts2ue.py --bs_npy_file ./records/2023-12-23-17-19-54.npy --wav_file ./records/2023-12-23-17-19-54.wav --fps 60
數據預處理
- 讀取records中的所有音頻文件,利用後驗編碼器,把音頻編碼後的隱變量z存入*.z.npy
- 寫入訓練和驗證用的文件列表
- filelists/val_visemes.list
- filelists/train_visemes.list
python ./motion/prepare_visemes.py
訓練
- 在train_ms.py 後加上--visemes來區別和主網的訓練
python train_ms.py -m OUTPUT_MODEL --config ./configs/config.json --visemes
推理
- 在webui.py執行時,將輸出的音頻、隱變量、動畫數據寫入當前目錄,可用tts2ue.py來查看生成效果
- 生成的動畫默認的fps是和隱變量一樣的86.1328125
- 44100/86.1328125 = 512,剛好整除,這是Bert-VITS2音頻採樣頻率、網絡結構和hidden_channels決定的
python ./motion/tts2ue.py --bs_npy_file ./tmp.npy --wav_file ./tmp.wav --delay_ms 700
聲音到表情
- 利用後驗編碼器,把聲音轉換成z,然後再把z轉成表情
- 音頻需轉成44100hz的wav文件,並只保留一個通道(ffmpeg)
# 音频截取转换
ffmpeg -i input_file -ss 00:00:00 -t 00:00:10 -ar 44100 -f wav test.wav
# 保留通道1
ffmpeg -i test.wav -map_channel 0.0.0 output.wav
python ./motion/wav_to_visemes.py output.wav
身體動畫
MotionGPT
- 有了語音和表情后,還可以在LLM驅動下產生與之匹配的動作描述,然後用text to motion模型生成與說話內容匹配的身體動畫,甚至和場景、他人進行交互。
- text to motion測試採用的項目是MotionGPT
- 暫未做動畫過度處理,看介紹模型是支持的motion in-between
- MotionGPT用的flan-t5-base,不能理解中文,所以無法用說話的文本產生同步度很高的動畫(翻譯成英文後語序多少有些變化)
- 是否可以用說話的文本或隱變量z來指導動作生成暫未可知
- MotionGPT輸出的是骨骼位置,與UE的骨骼動畫不能直接對接
- 目前用了簡化方法估算運動數值,會有不小的位置損失
- 計算出骨骼相對父節點的旋轉變化量(四元數)
- 通過OSC協議發送給VMCtoMOP程序,可預覽動畫,並做協議轉換
- 借助Mop插件將MOP數據映射給MetaHuman
audio2photoreal
- 在原項目的基礎上修改,Web界面推理時導出動畫數據到本地文件
- 導出過程
- 代碼https://github.com/see2023/audio2photoreal
Bert-VITS2 原版聲明
VITS2 Backbone with multilingual bert
For quick guide, please refer to webui_preprocess.py .
簡易教程請參見webui_preprocess.py 。
請注意,本項目核心思路來源於anyvoiceai/MassTTS 一個非常好的tts項目
MassTTS的演示demo為ai版峰哥銳評峰哥本人,並找回了在金三角失落的腰子
成熟的旅行者/開拓者/艦長/博士/sensei/獵魔人/喵喵露/V應當參閱代碼自己學習如何訓練。
嚴禁將此項目用於一切違反《中華人民共和國憲法》,《中華人民共和國刑法》,《中華人民共和國治安管理處罰法》和《中華人民共和國民法典》之用途。
嚴禁用於任何政治相關用途。
Video:https://www.bilibili.com/video/BV1hp4y1K78E
Demo:https://www.bilibili.com/video/BV1TF411k78w
References
- anyvoiceai/MassTTS
- jaywalnut310/vits
- p0p4k/vits2_pytorch
- svc-develop-team/so-vits-svc
- PaddlePaddle/PaddleSpeech
- emotional-vits
- fish-speech
- Bert-VITS2-UI
感謝所有貢獻者作出的努力


